
2021년 NeurIPS에서 발표된 “History aware multimodal transformer for vision-and-language navigation” 논문에 대해 정리한 글입니다.
 Summary
SummaryVision-Language-Navigation(VLN)에서 기존의 연구들은 RNN을 사용하여 히스토리를 구현한다. 하지만 초기 메모리는 RNN에서는 쉽게 희미해질 수 있다. 즉 히스토리 부족으로 인해 훈련 중 크로스모달 간의 정렬을 학습하기 어렵거나 과적합 될 수 있다. 또한 대부분 사전훈련된 BERT 인코더로 언어표현을 개선하거나 지시 및 관찰 쌍을 통해 멀티모달 트랜스포머를 사전에 훈련하는데, 이는 타겟을 탐색하는 일에 대한 시각적 표현을 최적화하지 못한다. 이러한 문제를 해결하기 위해 본논문은 장기간의 히스토리를 멀티모달 의사결정에 통합하고, hierarchical vision transformer를 통해 히스토리에 있는 모든 파노라마 관측을 효율적으로 인코딩하며, 현재 관측에서 이미지 간의 공간적 관계를 모델링하고 히스토리에서 파노라마 간의 시간적 관계까지 고려한 후, 텍스트, 히스토리, 현재 관측을 결합하여 다음 액션을 예측하는 history aware multimodal transformer(HAMT)를 제안한다.
Insights•
Hierarchical vision transformer를 통해 관측된 파노라마 액션의 장기간의 히스토리를 효율적으로 모델링하기 위한 방법을 제안한 연구로 전체 히스토리를 입력하여 관찰된 시각적 장면과 액션들을 인코딩하는 방법이 흥미로웠다.
•
또한 지시 및 관찰과 히스토리를 결합하여 멀티모달 액션 예측을 도툴하는 방법을 제안한 점, 그리고 프록시 테스크를 통해 엔드투엔드로 학습한 다음, 강화학습으로 파인튜닝하여, 네비게이션 정책을 개선한 점 역시 새로웠다.
Future works•
HAMT를 연속적인 액션이 있는 VLN으로 확장 및 더 큰 네비게이션 데이터셋에 대한 사전학습.

Vision Language Navigation(VLN)은 실제 상황에서 지시를 따르고 탐색하는 autonomous visual agent를 구축하는 것을 목표로한다. 즉 VLN은 agent가 시각 정보와 자연어 지시를 이용하여 목표 지점으로 이동하는 탐색 문제를 해결하는데 중점을 두고 있다.
Problem Statement
기존의 VLN 연구들은 몇가지 한계가 존재한다.
1.
대부분 RNN을 채택하여 고정된 크기의 상태 벡터 내에서 과거 관찰 및 액션을 인코딩하여 다음 액션을 예측하는데 이는 필수 정보를 캡처하는데 최적의 방법이 아니다. <숟가락 가져와> 지시가 주어졌을 때 agent는 지시된 숟가락으로 이동한 후 시작점을 기억해야 하는데 RNN에서 초기기억은 쉽게 희미해질 수 있다.
•
→ static vision-text grounding과 다르게 agent는 지속적으로 새로운 시각적 관찰을 수신하며 자신이 받은 지시와 일치시켜야 한다.
2.
보통 pre-trained BERT 인코더로 언어 표현을 개선하거나 지시 및 관찰 쌍을 사용해서 멀티모달 트랜스포머를 사전에 훈련한다. 하지만 이와 같은 방법들은 타겟 탐색 작업에 대한 시각적 표현을 최적화하지 못한다. 또한 훈련 중 히스토리가 부족하면 크로스모달 간의 정렬을 학습하기 어려워지고 과적합 될 확률이 높아진다.
•
→ 훈련 중에 관찰되지 않은 새로운 환경으로 agent를 일반화하는 것 또한 해결해야 될 과제이다.
이러한 이슈들을 해결하기 위해 본논문은 VLN 테스크에서 멀티모달 의사결정을 위한 트랜스포머 기반 아키텍처인 History Aware Multimodal Transformer(HAMT)를 제안한다. 따라서 본논문의 목표는 로 매개변수화된 policy()를 학습하여 지시, 히스토리 및 현재 관찰을 기반으로 다음 액션을 예측하는 것이다.
액션 예측을 위해 텍스트, 장기적 히스토리, 관찰을 공동으로 인코딩하는 HAMT에 대해 살펴보고자 한다.
Approach
History Aware Multimodal Transformer
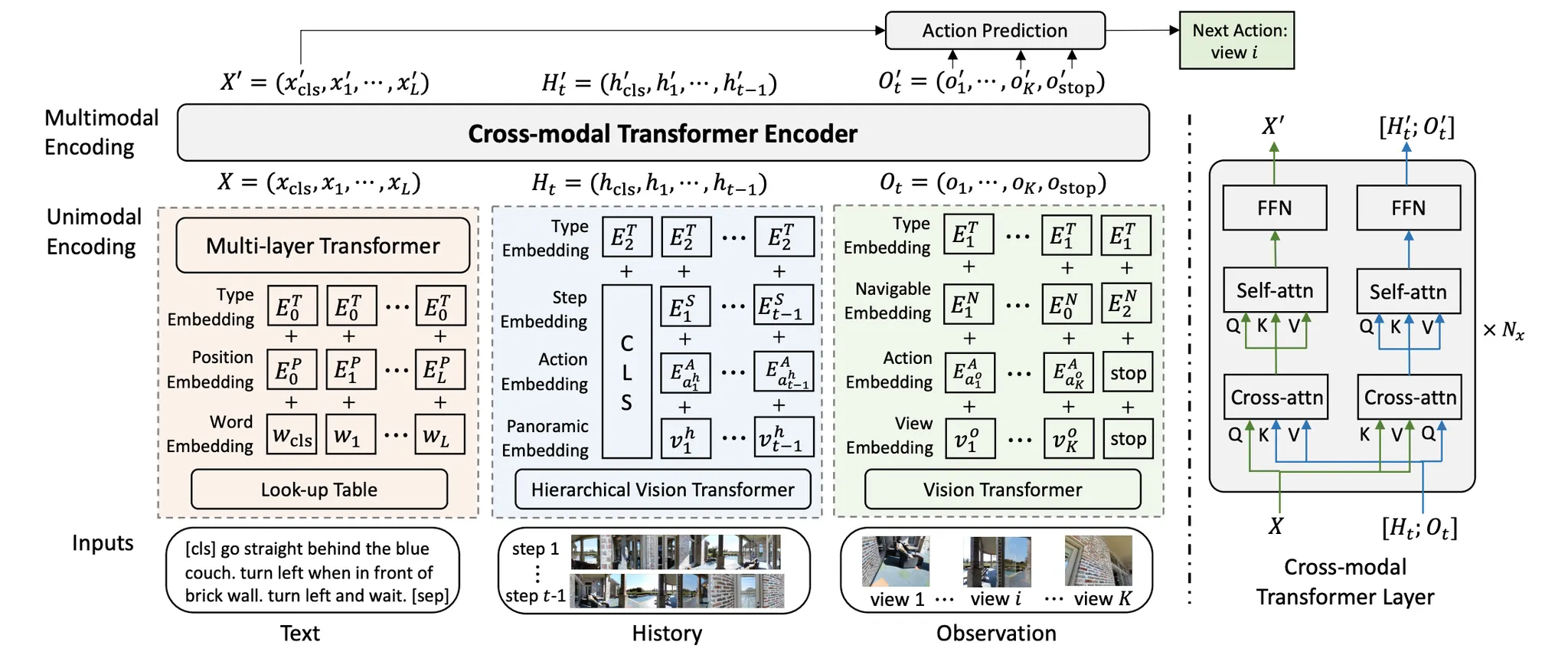
그림1. HAMT 아키텍처 (출처: 논문)
HAMT 구조에 대해 간단히 설명하자면, 위 그림에서 볼 수 있듯, HAMT는 텍스트, 히스토리, 관측 인코딩을 위한 각각의 유니모달 트랜스포머와 히스토리 시퀀스, 현재 관측 및 지시의 장거리 의존성을 캡처하기 위한 크로스모달 트랜스포머로 구성된다.
이때 히스토리에는 과거의 모든 관찰 시퀀스가 포함되어 있기 때문에 인코딩에 계산비용이 많이 든다. 따라서 복잡성을 해결하고자 아래의 그림2와 같이 단일 뷰에 대한 표현, 파노라마 내 뷰 간의 공간 관계, 히스토리 파노라마 전반의 시간적 다이나믹까지 점진적으로 학습하는 hierarchical vision transformer를 제안한다. 또한 더 나은 시각적 표현을 학습하기 위해 엔드투엔드 학습을 위한 auxiliary proxy task를 제안한다. (프록시 테스크에는 imitation learning에 기반한 single-step action, selfsupervised spatial relationship reasoning, maksed language and image predictions, instruction trajectory matching 등이 포함된다.)
아래에서 HAMT에 대해 좀더 자세히 살펴보도록 한다.
앞서 설명한 바와 같이 HAMT에서 텍스트(), 히스토리(), 관찰() 값들은 우선 각각의 유니모달 트랜스포머에서 인코드된 후, 서로 간의 멀티모달 관계를 포착하기 위해 크로스모달 트랜스포머로 반영된다. 즉 먼저 비전 트랜스포머로 개별 이미지를 인코딩한 다음 크로스 모달 트랜스포머를 사용해서 지시 및 현재 관찰의 유니 모달 트랜스포머 출력과 결합하는 방법이다.
우선 유니모달 트랜스포머에서의 인코딩 부분을 살펴보면 텍스트와 관찰 인코딩의 경우 그림1에 나온 것과 같이 인코딩된다 (자세한 사항은 논문을 참고하시길 바랍니다.) 여기서는 Hierarchical History Encoding 부분에 대해 좀더 자세히 살펴보려고 한다.
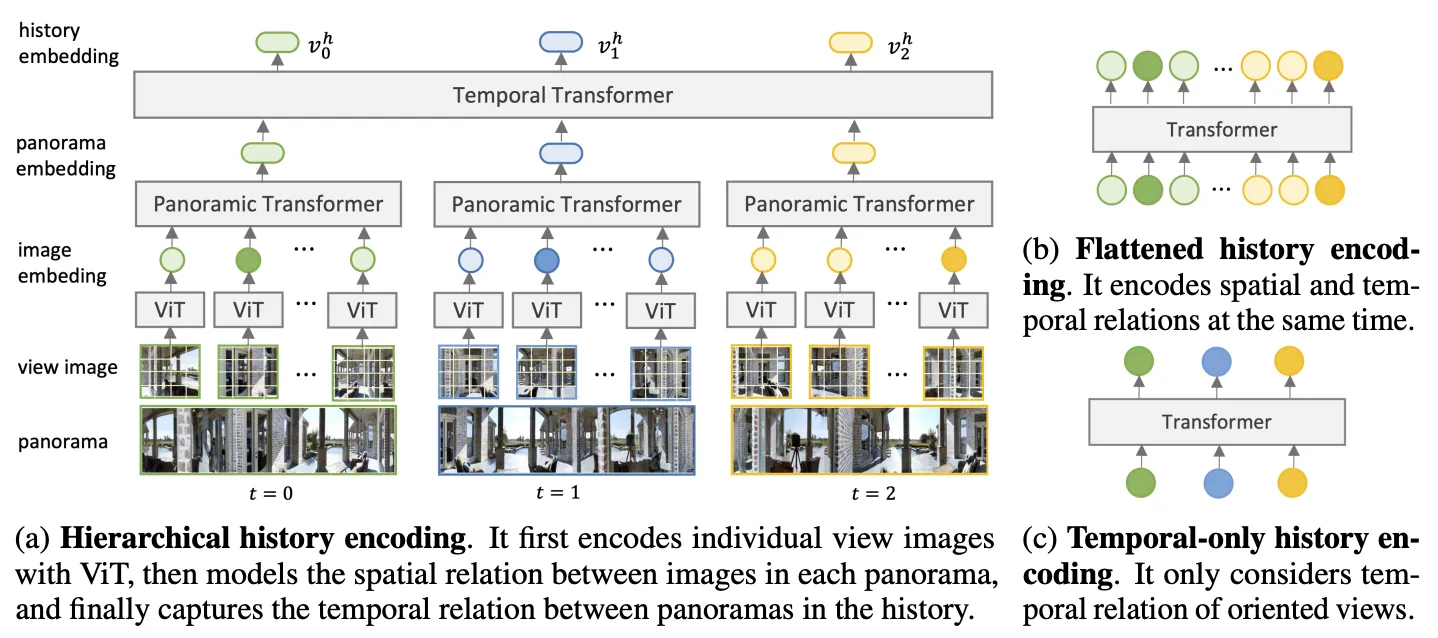
그림2. 히스토리 인코딩 방법들 (출처: 논문)
그림2의 (b)와 (c)는 각각 flattened & temporal-only 히스토리 인코딩을 보여주는데 이는 각각 VLN-BERT와 E.T에서 사용된 방법들이다. 그림2-(b) 모든 이미지 뷰들 간의 관계를 학습할 수 있지만 시퀀스 길이에 따라 계산 비용이 4배씩 증가하여 장시간의 테스크에는 비효율적이다. 그림2-(c) 전체 파노라마 대신에 agent의 보이는 뷰만 입력으로 사용한다. 하지만 이 경우 과거 관찰에서 얻은 중요한 정보를 손실할 수 있다. 예를 들어 <왼쪽에 창문이 있는 좌석 공간을 지나 큰 방으로 걸으세요> 지시에서 개체 <창문>은 agent의 방향에서 보이지 않는다. 따라서 인코딩된 히스토리만으로는 agent가 창문을 지나쳤는지 아닌지 알 수 있는 정보가 부족하고, 이는 agent가 다음 액션을 취하는 데 혼란을 준다.
따라서 그림2-(a)와 같이 hierarchical history encoding 방법을 본논문은 제안한다. 이는 파노라마 내의 뷰 이지미를 계층적으로 인코딩한 다음 파노라마 간의 시간적 관계를 인코딩하는데, 결과적으로 계산비용을 줄여주고 과거에 얻은 중요한 정보의 손실 역시 발생하지 않아 agent가 다음 액션을 취할 수 있도록 도와준다.
이와같이 유니모달 트랜스포머에서 인코딩된 후, 서로 간의 멀티모달 관계를 캡처하기 위해 크로스모달 트랜스포머로 반영된다. 여기서는 Cross-modal Encoding에 대해 좀더 자세히 살펴보려고 한다. 여기서는 히스토리와 관찰을 비전 모달리티로 연결하고 여러 레이어로 구성된 크로스 모달 트랜스포머를 사용하여 텍스트, 히스토리, 관찰의 피처들을 융합한다. 이때 듀얼스트림 아키텍처를 사용하는 이유는 서로다른 모달리티의 길이가 불균형할 수 있기 때문에 듀얼스트림으로 인트라 모달, 인터모달 관계의 중요도를 균형있게 맞춰준다.
크로스모달 트랜스포머의 학습 과정은 먼저 비전모달이 관련 텍스트 정보에 어텐션을 주고 텍스트 모달은 그 반대로 어텐션을 주며 vision-text cross-attention을 수행한다. 그후 각 모달리티는 self-attention을 사용하여 관찰과 히스토리 간의 상호작용 같은 모달 내의 관계를 학습한 다음 fully-connected neural net을 학습한다.
End-to-end training with proxy tasks
sparse supervision 때문에 RL과 함께 대규모의 트랜스포머를 훈련하는건 어렵다. 따라서 본논문은 유니모달과 멀티모달 표현을 학습하기 위해 여러 개의 프록시 테스크를 통해 HAMT를 엔드투엔드로 훈련하는 것을 제안한다.

표1을 보면 PREVALENT나 VLN-BERT은 텍스트, 히스토리, 관찰을 다같이 인코딩하지 않았기 때문에 훈련에 프록시 작업을 제한적으로 적용할 수 있다. 이에반해 HAMT는 다양한 프록시 작업을 활용하여 cross modal alignment, spatial and temporal reasoning, history-aware action prediction 등을 학습할 수 있다.
본논문에서는 VLN에 특화된 세가지 입력: 지시, 히스토리, 관찰이 주어졌을 때의 새로운 프록시 작업을 소개한다.
•
Single-step Action Prediction/Regression(SAP/SAR)
◦
Imitation learning을 사용해서 지시, 히스토리, 현재 관찰을 기반으로 다음 동작을 예측한다.
◦
탐색 가능한 각 뷰에 대한 액션 확률을 예측하는 SAP 분류와 텍스트 토큰 [cls]를 기반으로 액션 방향과 고도 각도를 예측하는 SAR 회귀를 제안한다. 이때 두 가지 프록시 테스크를 통해 모델은 지시 및 문맥적 히스토리에 따라 액션을 결정하는 방법을 학습할 수 있다.
•
Spatial Reltaionship Prediction(SPREL)
◦
보통 네비게이션 지시에서 우리는 자기 중심적 공간 관계와 할당 중심적 공간 관계 표현을 사용한다.
▪
예. 왼쪽 방으로 걸어 들어가(자기 중심적 공간 관계), 계단 옆 침실로 들어가(할당 중심적 공간 관계)
◦
공간 관계 인식 표현을 학습하기 위해 시각적 피처, 각도 피처, 또는 둘다에 기반하여 파노라마에서 두 뷰의 상대적 공간 위치를 예측하는 SPREL self-supervised task를 제안한다. 이 테스크는 관찰 내에서 공간 관계 추론에 도움을 준다.
•
Training Strategy
◦
HAMT 전체 모델을 한 번에 훈련하는 대신 두 단계로 나눠 점진적으로 훈련한다.
▪
1-단계에서는 ImageNet에서 사전훈련된 ViT를 프리징하고, 나머지 모듈을 무작위로 초기화해서 훈련한다. 이 경우 ViT에서 사전훈련된 가중치를 잊어버리는 것을 방지하는 것이 목표이다.
▪
2-단계에서는 ViT 프리징을 해제하고 전체 모델을 엔드투엔드로 훈련한다. ViT의 학습 속도는 다른 모듈보다 높게 설정해서 그라이언트 소실을 방지하고 수렴 속도를 높인다.
Fine-tuning for sequential action prediction
•
Structure Variants
◦
MLP action head
▪
탐색 가능한 뷰를 예측하기 위해 SAP에서 액션 예측 네트워크를 직접 재사용.
▪
VLN 작업에는 기본으로 사용.
◦
인코더 디코더 구조에 기반한 MLP action head
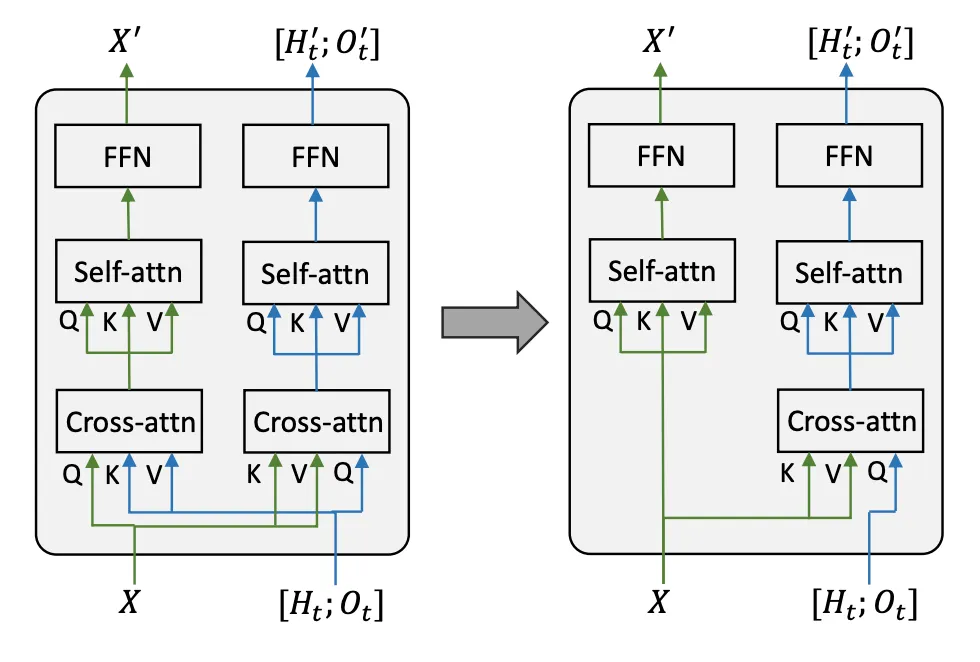
그림3. (왼)크로스 모달 트랜스포머 레이어와 (오)인코더-디코더 변형 비교.
▪
기존 HAMT 모델은 비전-텍스트 및 텍스트-비전 모두에 대해 크로스 모달 어텐션을 적용하는데 이는 지시어가 길면 계산 비용이 많이 발생.
▪
따라서 그림의 오른쪽과 같이 텍스트-비전 크로스 모달 어텐션 제거. 인코더는 텍스트를 인코딩하여 텍스트 임베딩을 얻고, 디코더는 각 네비게이션 단계에서 비전-텍스트 어텐션 레이어에 동일한 텍스트 임베딩 재사용. 즉, 크로스 모달 트랜스포머를 지시만 입력으로 받는 인코더와 히스토리와 관찰을 쿼리로 입력하고 인코딩된 텍스트 토큰을 처리하는 디코더로 분리.
▪
이는 지시어가 긴 경우 효율적.
•
RL+IL Objective
◦
강화학습(RL)과 모방학습(IL)을 결합하여 순차적인 액션 예측을 위해 HAMT를 파인튜닝.
◦
IL은 SAP 손실에 의존 & 각 단게에서 expert 액션 따르고, RL은 policy에 따라 액션을 샘플링.
◦
이때 RL 알고리즘으로는 Asynchronous Advantage Actor-Critic (A3C) 사용.
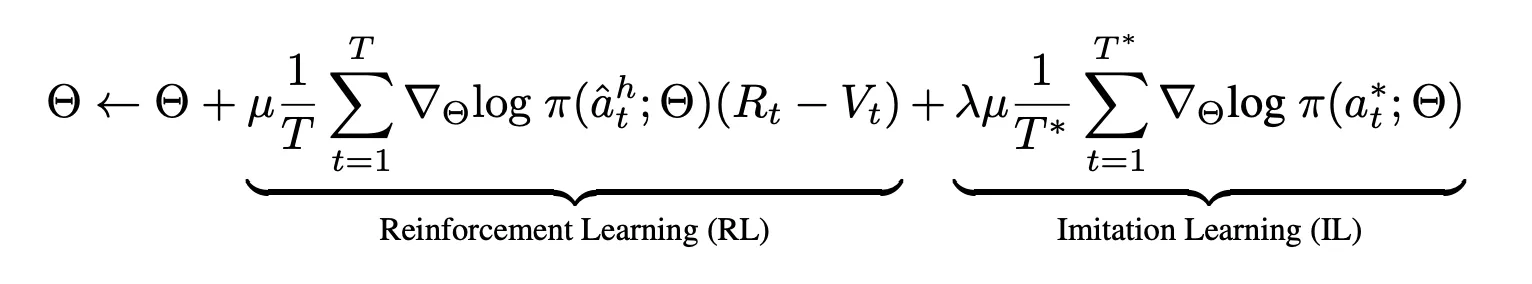
Experiments
Datasets
•
•
•
long-horizon → R4R, R2R-Back
Metrics
•
Trajectory Length(TL)
◦
agent가 탐색한 경로(미터)
•
Navigation Error(NE)
◦
agent의 최종 위치와 목표지점 사이의 평균 거리(미터)
•
Success Rate(SR)
◦
목표지점에 대해 최대 오차 3미터로 목적지에 도달한 궤적의 비율
•
SPL
◦
최단 경로 길이와 예측 경로 사이의 비율로 정규화된 성공률
◦
네비게이션 정확도와 효율성 간의 균형을 맞추기 때문에 SR보다 적절
추가적으로 R4R & R2R-Back 같은 long-horizon VLN task의 경우 예측경로와 목표경로 사이의 경로 충실도 측정을 위해 아래 세가지 메트릭을 사용한다.
•
Coverage weighted by Length Score(CLS)
•
normalized Dynamic Time Warping(nDTW)
•
Success weighted by nDTW(SDTW)
Ablation studies
•
How important is the history encoding for VLN?
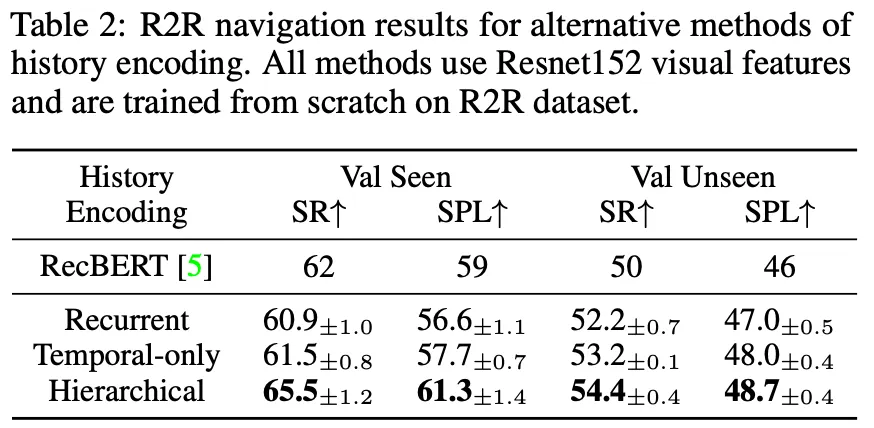
◦
Hierarchical History Encoding을 살펴보기 위해, RecBERT와 그림2에서 본 Recurrent, Temporal-only와 비교하였고 이를 통해 hierarchical history encoding의 우수성을 선보임.
•
How much does training with proxy tasks help?
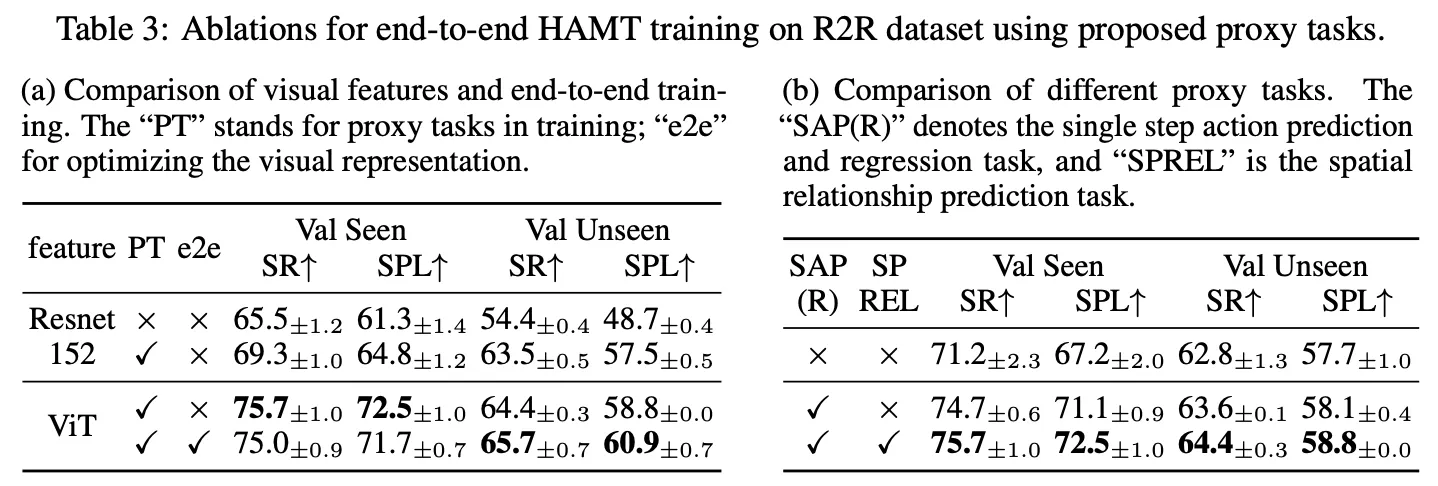
◦
프록시 테스크를 통해 엔드투엔드 HAMT를 훈련할 때의 이점을 살펴본 실험으로 프록시 작업으로 먼저 훈련하면 성능이 크게 향상되는 걸 알 수 있다. 그리고 피처를 ViT로 대체했을 때 성능이 좋아진다는 걸 통해 시각적 표현의 중요성을 알 수 있고, ViT를 엔드투엔드로 최적화하는 것이 VLN에서 유리하다는 걸 알 수 있다.
◦
표3-(b)에서 SAP(R)은 imitation learning을 사용해서 액션을 예측하므로 네비게이션 정책에 직접적인 영향을 미치게 되고 따라서 성능이 큰폭으로 개선된다. SPREL은 모델이 파노라마에서 공간 관계를 학습하도록 하고 보이지 않는 환경에서도 일반화를 지원하는 self-supervised 프록시 테스크이다.
•
What is the impact of the fine-tuning objectives?
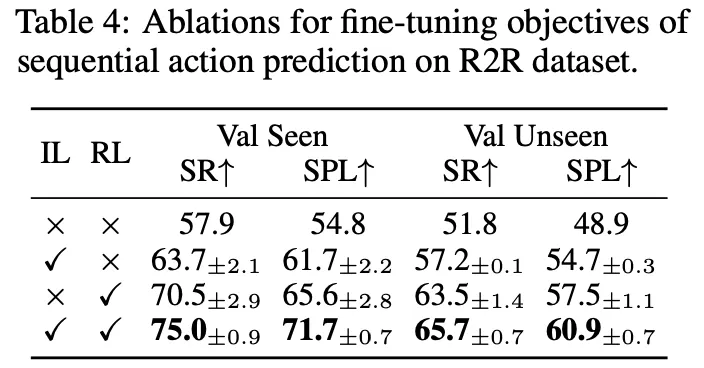
◦
HAMT는 IL로 파인튜닝 됐을 때 보다 RL로 최적화 됐을 때 더 나은 성능을 보여준다. 그렇지만 RL에 대한 보상은 지시에 따른 경로 충실도 보다 최단 경로에 더 중점을 두기 때문에 SPL 지표 개선이 SR 값보다 작다. 따라서 RL과 IL을 같이 써야 최상의 성능을 얻을 수 있다는 걸 알 수 있다.
Comparison to state-of-the-art
•
VLN with fine-grained instructions: R2R and RxR.
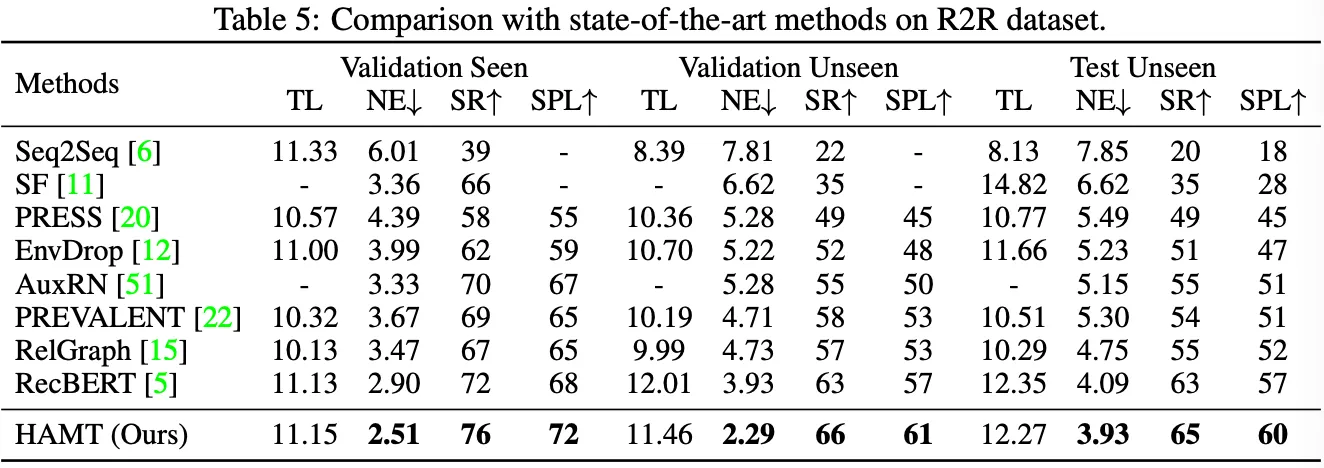
◦
논문이 제안한 HAMT 모델이 val seen과 val unseen 각각에서 RecBERT보다 우수한 성능을 보여준다. Test unseen 결과의 경우 HAMT의 뛰어난 효율성과 일반화를 보여분다.
•
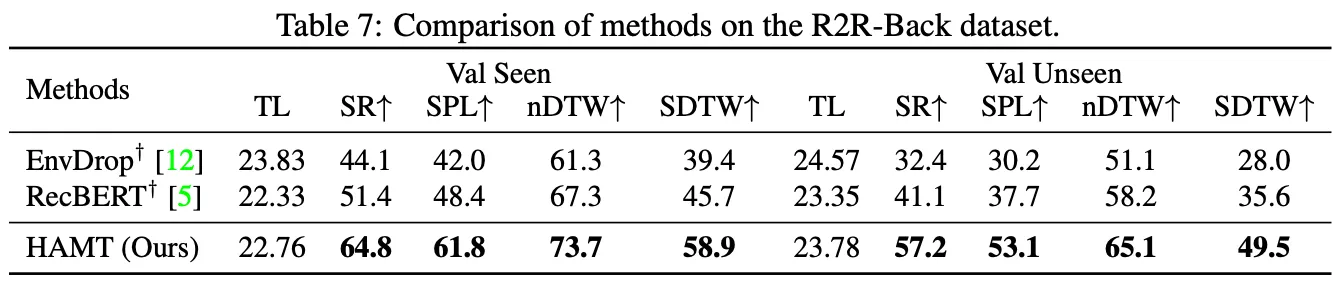
Long-horizon VLN: R4R and R2R-Back.

◦
R4R은 긴 지시와 긴 궤적을 포함하는 데이터셋.
◦
The large improvements on these path fidelity related metrics indicate that HAMT is better to follow the designated path of the fine-grained instruction.
◦
그림3은 단어 기반으로 긴 지시에 대해 HAMT와 RecBERT의 성능을 평가한 그래프이다. 지시 길이가 길어질 수록 nDTW는 감소하지만, 지시 길이가 길어질 수록 HAMT의 상대적 개선은 증가한다.
◦
각각 LSTM과 트랜스포머 기반인 EnvDrop과 RecBERT를 HAMT와 비교한 결과.
◦
agent가 성공적으로 복귀하기 위해서는 목표에 도달한 경로를 기억해야 하는데, RNN의 경우 이와 같은 히스토리를 캡처하기 충분하지 않다. 따라서 HAMT 모델이 성능이 더 우수한 것을 알 수 있다.
•
Vision-and-Dialog Navigation: CVDN.
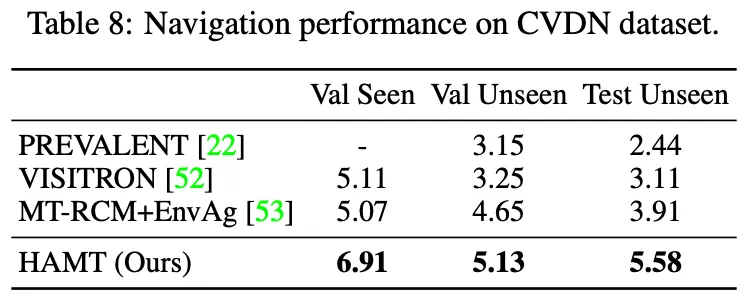
◦
CVDN은 대화가 포함되어 있고, 최단 경로 궤적과 플레이어의 네비게이션 궤적 두가지 유형의 데모가 있으며, 미터 단위의 Goal Progress(GP)를 기본 평가 지표로 사용. GP는 목표까지 완료한 거리와 남은 거리 간의 차이를 측정하기에 값이 높을 수록 좋다.
◦
CVDN 데이터셋의 네이게이션 경로는 R2R보다 길기 때문에 HAMT의 인코더-디코더 변형을 사용했고, 표8를 통해 알 수 있듯 기존의 RNN 방식들보다 성능이 뛰어나다는 것을 알 수 있다. 즉 HAMT 모델이 새로운 VLN 테스크에서 다양한 유형의 지시에 일반화할 수 있다는 걸 보여준다.
•
VLN with high-level instructions: R2R-Last and REVERIE.
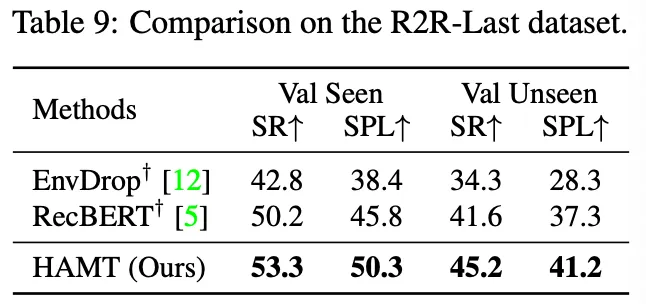
◦
표9는 목표 위치를 지정하고 단계별 지시는 포함되지 않은 R2R-Last 데이터셋의 결과를 보여준다. hierarchical history encoding을 사용하는 HAMT 모델은 환경에 대한 지식을 더 잘 축적할 수 있다는 사실을 결과를 통해 알 수 있다.
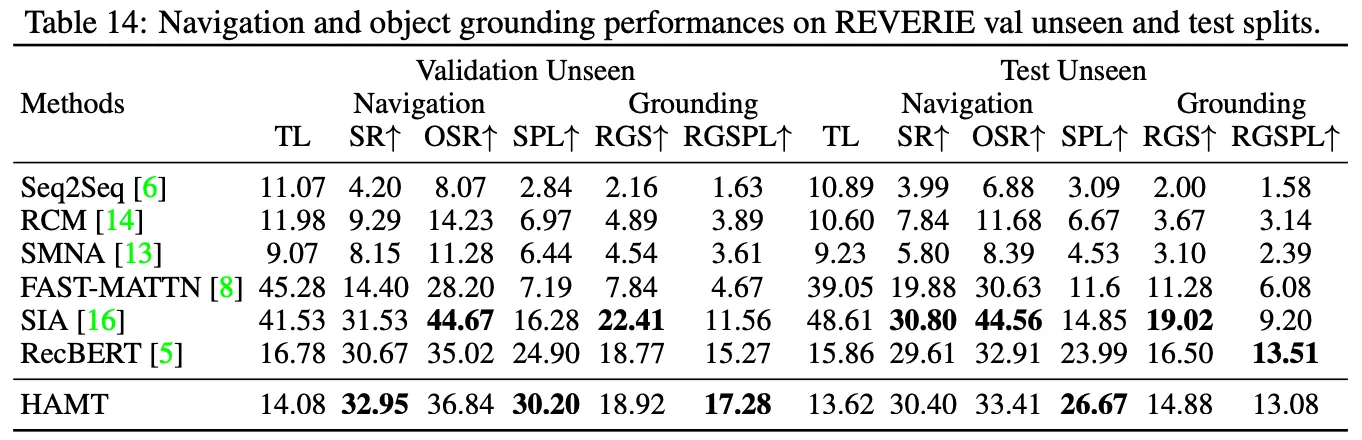
◦
REVERIE 데이터셋에는 높은 수준의 지시도 포함되어 있지만 네비게이션 외에 목표 위치에 대한 객체 그라운딩이 필요. R2R 데이터셋에서 엔드투엔드 사전학습된 HAMT를 파인튜닝하고, 최적화된 ViT를 사용해서 REVERIE 데이터셋의 groundtruth object bounding boxes가 주어진 객체 피처를 추출한다.
◦
표14를 통해 HAMT는 네비게이션 성능은 우수하지만 테스트 분할에서 Grounding 성능은 다른 최신 연구보다 다소 떨어진다는 걸 알 수 있다. 왜냐하면 R2R 데이터셋에 최적화된 ViT를 사용해서 객체 피처를 추출하기 때문에 대규모의 객체 탐지 데이터셋에서 사전학습된 객체 피처에 비해 표현이 일반화되지 않을 수 있다.
•
History encoding in long-horizon VLN task
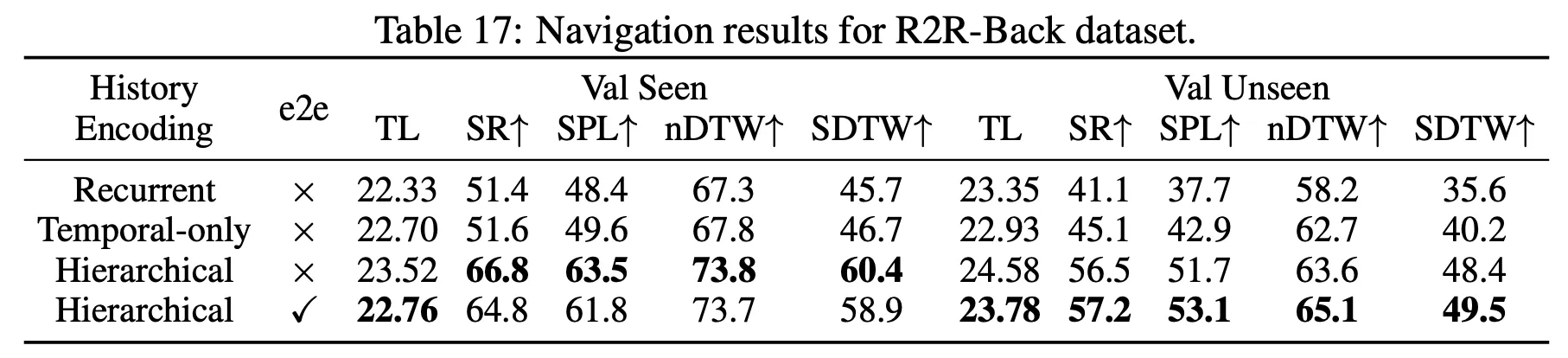
◦
R2R-Back 데이터셋에서 다양한 히스토리 인코딩 방식을 비교하여 히스토리 정보가 장거리 VLN 작업에서 유리하다는 걸 보여주는 실험이다.
◦
backward trajectory의 agent의 방향뷰는 forward와는 다르기 때문에 temporal-only 모델은 이전 탐색의 전체 메모리를 활용하지 못하고, hierarchical history 인코딩 모델보다 성능이 떨어지는 걸 알 수 있다. 즉 장기적인 의존성이 요구되는 long-horizon VLN 작업에서 논문이 제안한 방법이 효과적이라는 걸 알 수 있다.
기존의 RNN 연구가 보여준 한계점인 장기간의 히스토리를 효율적으로 인코딩하는 방법과, 지시 및 관찰과 이를 결합하여 멀티모달 액션 예측을 도출하는 방법을 제안한 점이 흥미로운 논문이었다. 또한 프록시 테스크를 통해 엔드투엔드로 학습한 다음, 강화학습으로 파인튜닝하여, 네비게이션 정책을 개선한 점도 새로웠다.
물론 성능평가에서 Object Grounding 성능이 다소 떨어지는 것을 볼 수 있었다. 따라서 object detection으로 사전훈련된 데이터셋에 최적화된 모델을 사용해보는 방법도 좋지 않을까 라는 개인적인 생각이 든다. 실험에서 궁금한게 있는데 같은 hierarchical encoding을 했을 때 엔드투엔드 방식 여부에서 더 성능이 뛰어난 경우가 있고 아닌 경우가 있는데 이는 어떤 차이 때문일까. 엔드투엔드 방식으로 훈련한 경우 보이는 환경보다 보이지 않은 환경 탐색에서 더 성능이 뛰어난 부분도 신기하다.