

Contrastive Learning이 제안된 이후 Image분야에서는 이 방법을 많이 사용하기 시작했었는데요. 최근 대규모 데이터셋 기반 multimodal learning이 급부상함에 따라 contrastive 방법을 사용한 논문들이 여전히 쏟아지고 있습니다. 따라서 SimCLRv2 논문을 토대로 Contrastive Learning에 대해 설명하는 글을 정리했습니다.

왼쪽 그림은 무엇일까? 우리는 이 그림이 무엇인지 바로 설명할 수 있다: “갈색, 흰색 털이 섞인 귀여운 고양이가 걷고 있다”. 하지만 이 그림을 컴퓨터에 보여주면 컴퓨터는 이미지를 바로 설명할 수 있을까? 그렇지 않다. 컴퓨터에게 고양이 그림은 RGB 값에 해당하는 픽셀의 배열일 뿐이다.
하지만 우리는 컴퓨터가 우리와 유사한 방식으로 이미지를 해석할 수 있길 바란다. 즉 컴퓨터가 높은 수준의 특징이 포함된 이미지의 짧은 요약을 생성해내길 바란다.
머신러닝에서는 이를 일반적으로 Representation Learning이라고 한다. 큰 이미지를 작은 벡터에 매핑하는 네트워크를 학습하여 사진의 세부사항은 버리고, 보다 더 추상적인 특징에 초점을 맞추는 것이다. 위 그림과 같이 예를 들어보면, 고양이 이미지에서 작은 벡터에 털 한올한올이 무슨 색상인지 대신 이미지에 고양이가 있다는 정보가 포함되는 것인데. 이 경우 학습된 표현은 중요한 정보를 유지하면서 훨씬 간결하기 때문에 원래 원본 이미지에서 수행했던 분류나 객체탐지 같은 작업들이 저차원 입력 표현을 통해 더 빠르게 학습할 수 있다.
컴퓨터가 방대한 양의 레이블이 없는 이미지를 활용하여 어떻게든 스스로 의미 있는 표현을 얻을 수 있다면 정말 좋을 것 같은데. 바로 이 문제가 Contrastive Learing이 해결하고자 하는 문제이다.
1. What Contrastive Learning is?
Contrastive Learning은 self-supervised representation learning 중에서 가장 유망한 방식 중 하나로 입증되었다. Contrastive Learning은 기본개념은 간단한데, 유사한 이미지가 저차원 공간에서 서로 가깝게, 동시에 다른 이미지는 서로 멀리 떨어져있도록 저차원 공간에서 이미지를 인코딩하는 방법을 모델이 학습하는 것이다.
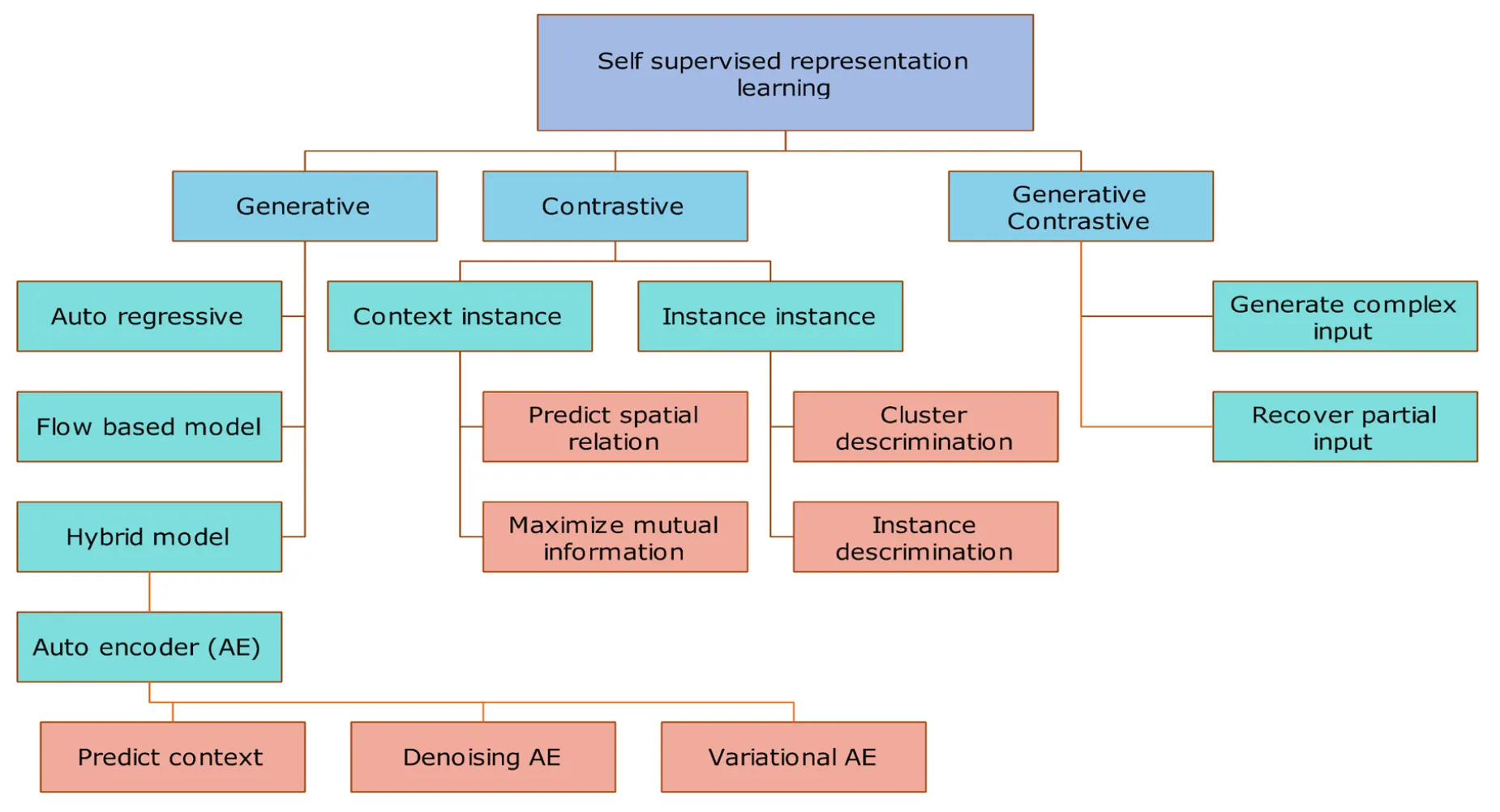
- 참고자료[14] Contrastive self-supervised learning review 논문 그림.
위 그림과 같이 self-supervised representation learning을 수행할 수 있는 방법은 다양하다. 그중 널리 사용되는 방법으로는 Variational Autoencoder(VAE)와 Generative Adversarial Networks(GANs)가 있다. 인코더만 학습하는 Contrastive Learning과 다르게 VAE와 GANs은 모두 학습된 저차원 표현을 원래의 이미지로 다시 변환할 수 있게 하는 디코더를 가지고 있다.
반면 Contrastive Learning은 학습된 표현 공간 내에서 이미지 간의 거리를 직접 조절하려고 시도한다. 아래 그림과 같이 고양이 이미지 표현은 다른 고양이 이미지 표현과 가까워야 하고, 돼지 이미지는 고양이 이미지 표현과 멀리 떨어져야 한다.
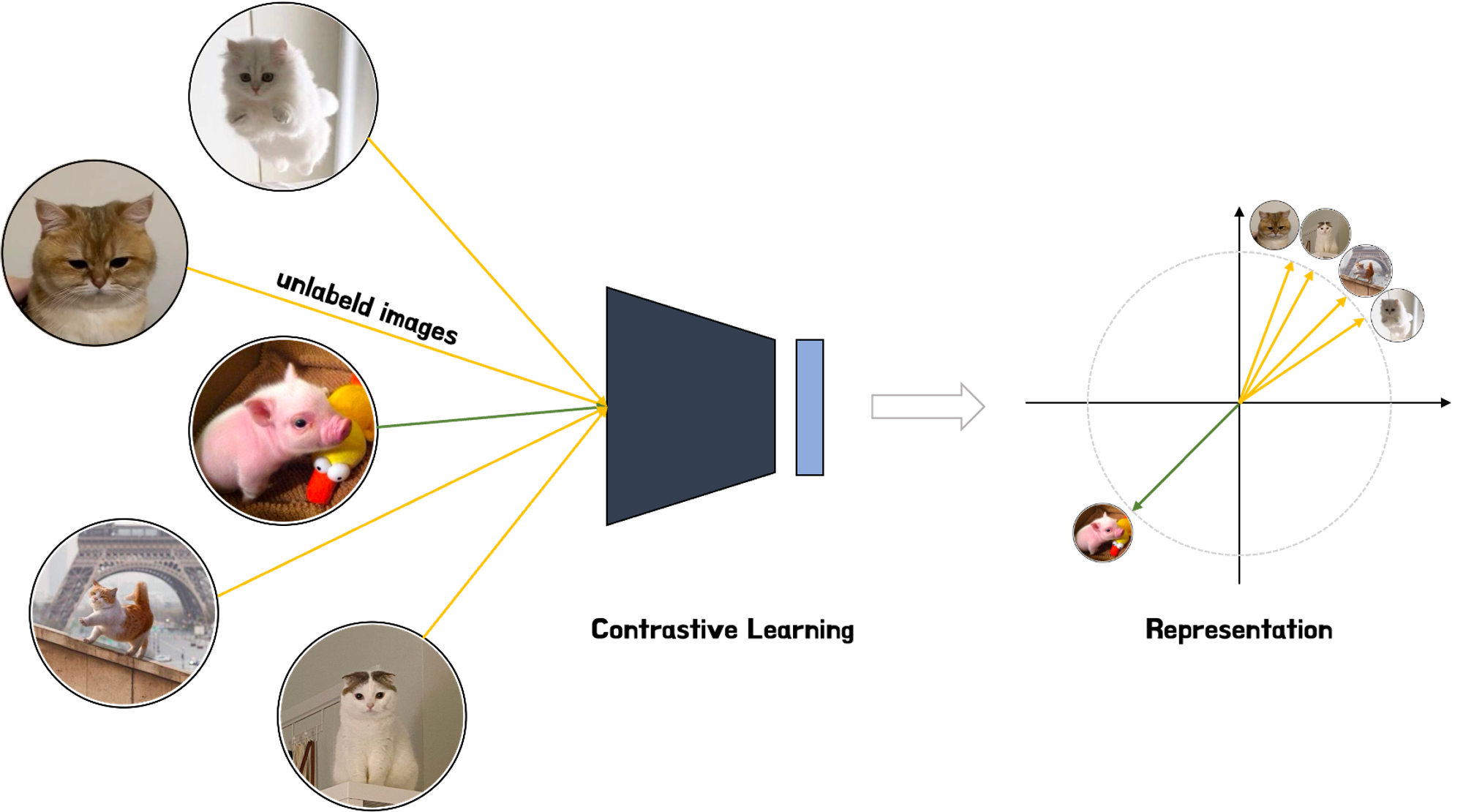
다시 설명하자면 Contrastive Learning은 Self-supervised visual representation learning으로 (1)유사한 양수 쌍 또는 샘플들의 표현 사이의 거리를 최소화하고 (2)다른 음수쌍 또는 샘플의 표현 사이의 거리를 최대화하여 특징을 추출 학습하는 방법이다. 좀더 쉽게 설명하자면, contrastive learning은 분류나 세분화 같은 작업을 수행하기 전에 데이터에 대한 상위 수준의 특징을 학습하기 위해 어떤 데이터 포인트 쌍이 유사하고 상이한지 살펴보는 머신러닝 방법이다.
위 그림을 예로 들면, 고양이 사진 4장과 돼지 사진 1장이 입력으로 주어졌을 때, contrastive learning을 통해 주석이나 레이블 없이 유사한 값들은 가깝게, 상이한 값은 멀리 떨어져 표현되는 것을 볼 수 있다. 즉, contrastive learning의 목표는 특정 예측을 생성하기 위해 모델을 최적화하는 것이 아니라 표현 자체가 의미있는지 확인하는 것임을 알 수 있다.
이와 같은 방법이 효과적인 이유는 대부분의 리얼월드 상황에서는 각 이미지에 대한 레이블이 없기 때문이다. 따라서 레이블을 생성하려면 전문가가 이미지를 수작업으로 분류하고 세그먼트화하는 등 수많은 시간을 들여야 하기에 쉽지 않다. 하지만 contrastive learning을 사용하면 주석이나 레이블 없이도 데이터에 대해 많은 것을 학습하도록 모델을 훈련시킬 수 있다.
그렇다면 Contrastive Learning은 어떻게 학습될까?
2. How Contrastive Learning works?
Contrastive Learning은 레이블이 지정되지 않은 데이터셋에서 contrastive loss를 최소화하는 인코더 파라미터를 찾는다. 이때 contrastive loss는 학습된 표현에서 비슷한 이미지는 서로 가깝게, 다른 이미지는 서로 멀리 떨어져있길 원한다는 ‘contrastive’ 개념을 구현한다.
이해를 돕기위해 SimCLRv2 논문[17]을 예로 들어 설명하고자 한다.

데이터셋의 각 이미지에 대해 crop+resize, crop+recolor와 같은 증강 조합(augmentation combination)을 수행할 수 있다. 이 두 이미지는 본질적으로는 동일한 이미지의 다른 버전이므로 모델이 두 이미지가 유사하다는 것을 학습하길 원한다. (*data augmentation은 contrastive learning의 핵심 중 하나이다.)

이를 위해 두 이미지를 CNN과 같은 딥러닝 모델에 입력하여 각 이미지에 대한 벡터 표현을 만든다. 이때 목표는 유사한 이미지에 대해 유사한 표현을 출력하도록 모델을 훈련 시키는 것이다.
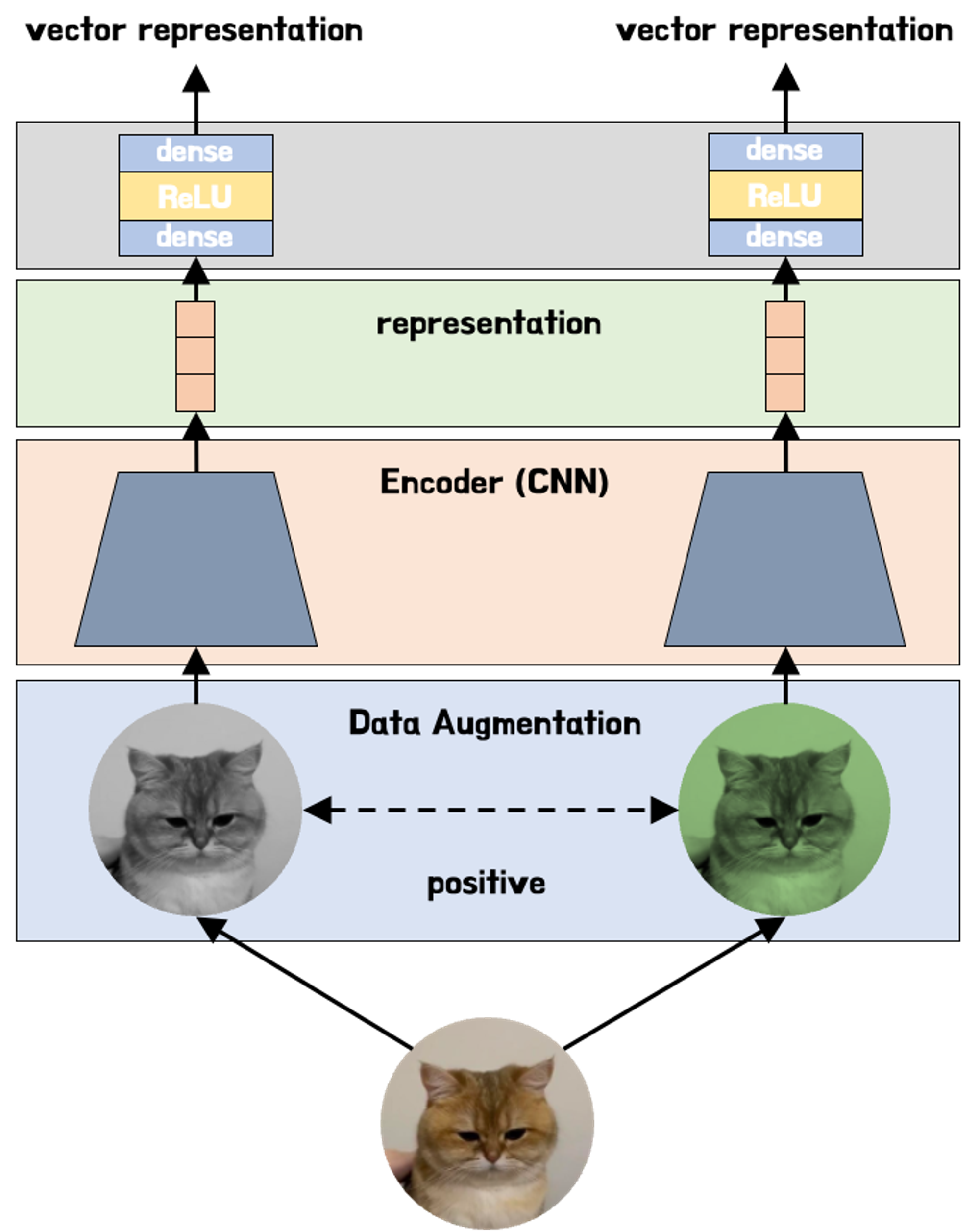
마지막으로 contrastive loss를 최소화하여 두 벡터 표현의 유사성을 최대화한다. 시간이 지남에 따라 모델은 두 고양이 이미지가 비슷한 표현을 가져야 하고, 고양이 표현은 돼지와 달라야 한다는 것을 학습하게 된다. 즉 모델은 이미지가 무엇인지 알지 못해도 서로 다른 유형의 이미지를 구별할 수 있게 된다.
그렇다면 여기서 말한 contrastive loss는 무엇일까?
3. What Contrastive Loss is?
Contrastvie Loss는 벡터 사이의 유사성을 정량화하는 방법으로 간단하게 설명하면 positive loss와 negative loss를 합친 값으로 같은 이미지일 수록 가깝게 즉 positive loss는 적게, 다른 이미지일 수록 멀게 즉 negative loss는 멀게 임베딩을 표현하는 손실함수이다. 위에서 설명한 SimCLRv2 논문[17]은 NT-Xent(Normalized Temperature-Scaled Cross Entropy Loss)를 제안했고, 이는 현재까지도 널리 사용되는 방법 중 하나이다.
여기서는 NT-Xent[17]를 토대로 Contrastive Loss를 설명하려고 한다.

두 벡터의 유사성을 구하는 가장 간단한 방법은 Cosine Similarity로 벡터 공간에서 두 벡터가 가까울 수록 더 유사한 행태를 지니게 되는데, Contrastvie Loss 역시 두 벡터 사이의 각도를 취하면서 각도가 0일 때 높은 유사성을 지니고 그렇지 않을 때 낮은 유사성을 보이는 것을 구하고자 한다.
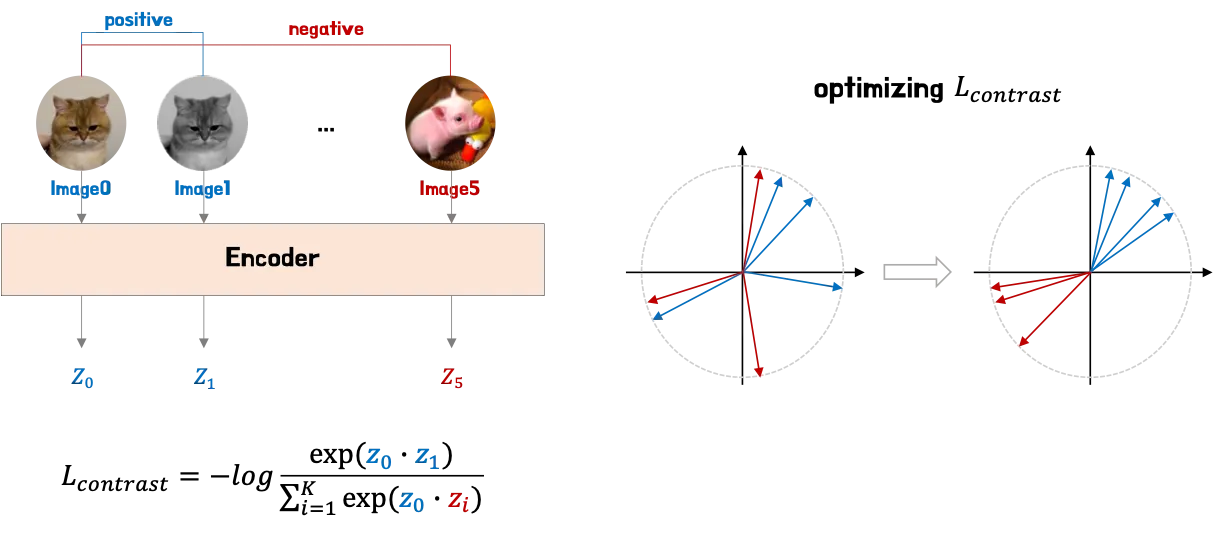
Contrastive learning의 경우 위 그림에서 볼 수 있듯, 먼저 contrastive loss 계산을 위해 데이터셋에서 i-개의 이미지를 샘플링한다. 이때 이미지 0과 1은 나머지 이미지와 다른 유사한 이미지이다. 그후 인코더를 통해 각 이미지에 대한 표현(zi)을 얻는다. 벡터 간의 유사성을 측정하기 위해 dot product를 사용한다. Contrastive loss을 최소화하면 z0과 z1 사이의 dot product 값이 증가하고 나머지 이미지와의 값은 감소한다. 결과적으로 위 그림의 오른쪽 그림과 같이 유사한 이미지들의 표현은 더 가까워지고 나머지 이미지 표현과는 멀어진다.
4. Applications of Contrastive Learning
4.1. Supervised Learning
Self-Supervised Learning에서만 폭발적인 성능을 보여줄 것이라 예상했던 바와 달리, Supervised Learning에서도 Contrastive Learning을 활용할 수 있는 것으로 밝혀졌다[13].
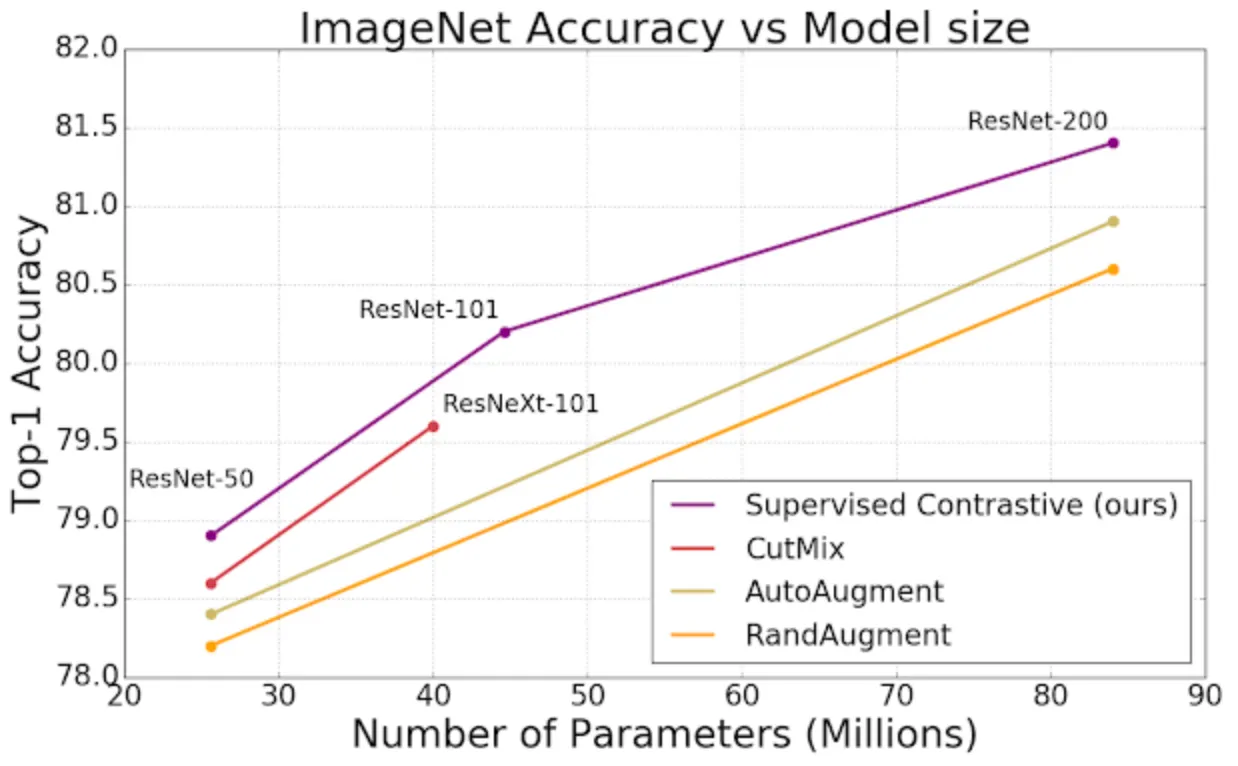
- 참고자료 [13] Extending Contrastive Learning to the Supervised Setting에서의 표
구글이 발표한 논문[13]을 통해 알 수 있듯, Supervised Contrastive Learning은 위 그림과 같이 ImageNet에서 엄청난 성능을 보여주었다. 일반적으로 Supervised learning은 분류기를 end-to-end로 훈련한다. 즉 이미지를 신경망에 입력하고 레이블의 원핫 인코딩된 벡터에 대한 cross-entropy loss을 계산한다.
그러나 Supervised Contrastive Learning은 훈련 절차가 다음과 같이 두 단계로 나뉘어진다.
1.
Supervised contrastive loss를 최적화하여 이미지를 표현으로 인코딩하는 인코더를 학습
2.
인코더를 고정하고 학습된 표현을 받아 클래스 레이블을 출력하는 선형 레이어를 추가
이때 두번째 단계는 우리가 흔히 알고있는 supervised learning과 동일한 방식이다.
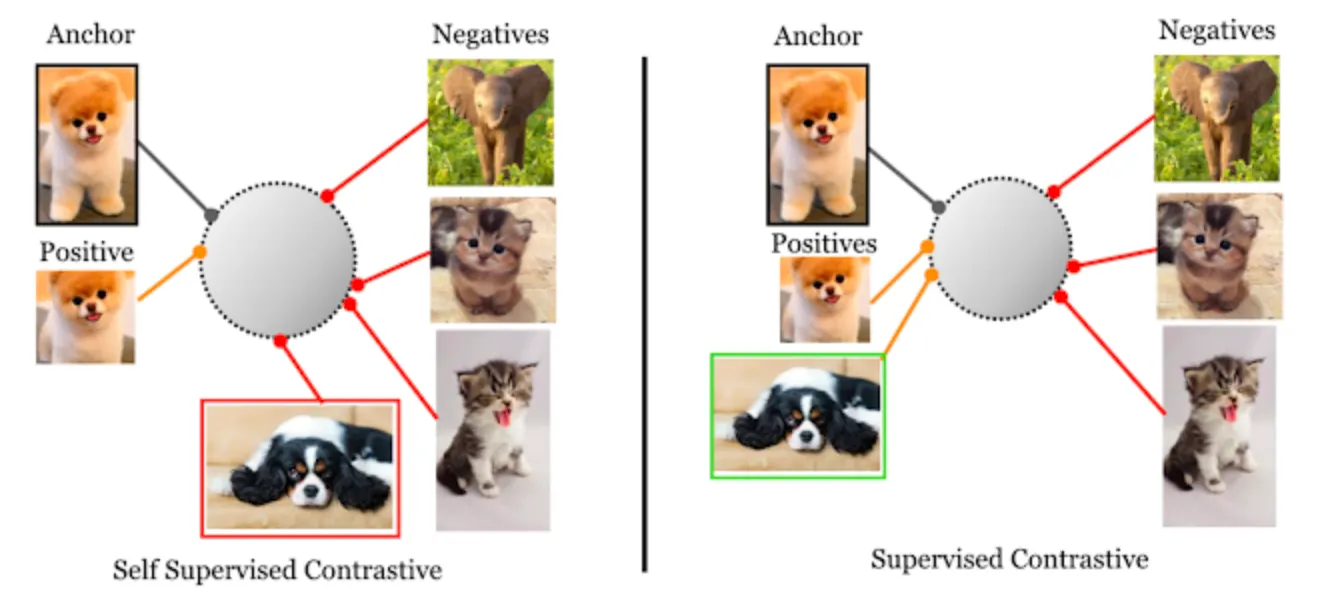
- 참고자료 [13] Extending Contrastive Learning to the Supervised Setting의 그림
Supervised contrastive loss는 클래스 레이블에 의미적으로 유사한 이미지를 얻기 위해 데이터 증강이 필요한 self-supervised learning과 다르게, 이미지 레이블을 간단히 비교하여 “서로 끌어당길 것인지” 아니면 “더 밀어낼 것인지”를 결정할 수 있다.
위 그림에서 알 수 있듯 오른쪽 그림은 supervised contrastive이다. 클래스1에 속하는 모든 이미지(강아지)는 학습된 표현에서 한 곳에 모이게 되는데, 동시에 클래스2에 속하는 이미지(고양이)는 반대편으로 튕겨지게 된다.
왼쪽 그림과 같이 self-supervised contrastive의 경우, ‘positive’ 클래스는 동일한 이미지의 증강으로 구성되고, 이 경우 이외에 데이터셋의 다른 모든 이미지는 ‘negative’로 표시될 수 있다. 즉, ‘positive’ 클래스와 같은 강아지 이미지라도 동일한 이미지 증강으로 구성된 샘플도 아니고, 더구나 레이블마저 없기 때문에, ‘negative’ 클래스로 분류될 수 있는 문제가 있다.
이와같은 문제로 Contrastive learning이 supervised learning에서 더 좋은 성능을 나타내게 된다.
4.2. Multimodal Representation Learning
Multimodal Representation Learning에서의 contrastive learning은 최근 각광을 받고 있는 추세이다. 따라서 이 부분에 대한 설명은 각각의 논문에서 사용된 contrastive learning 설명으로 대체한다.
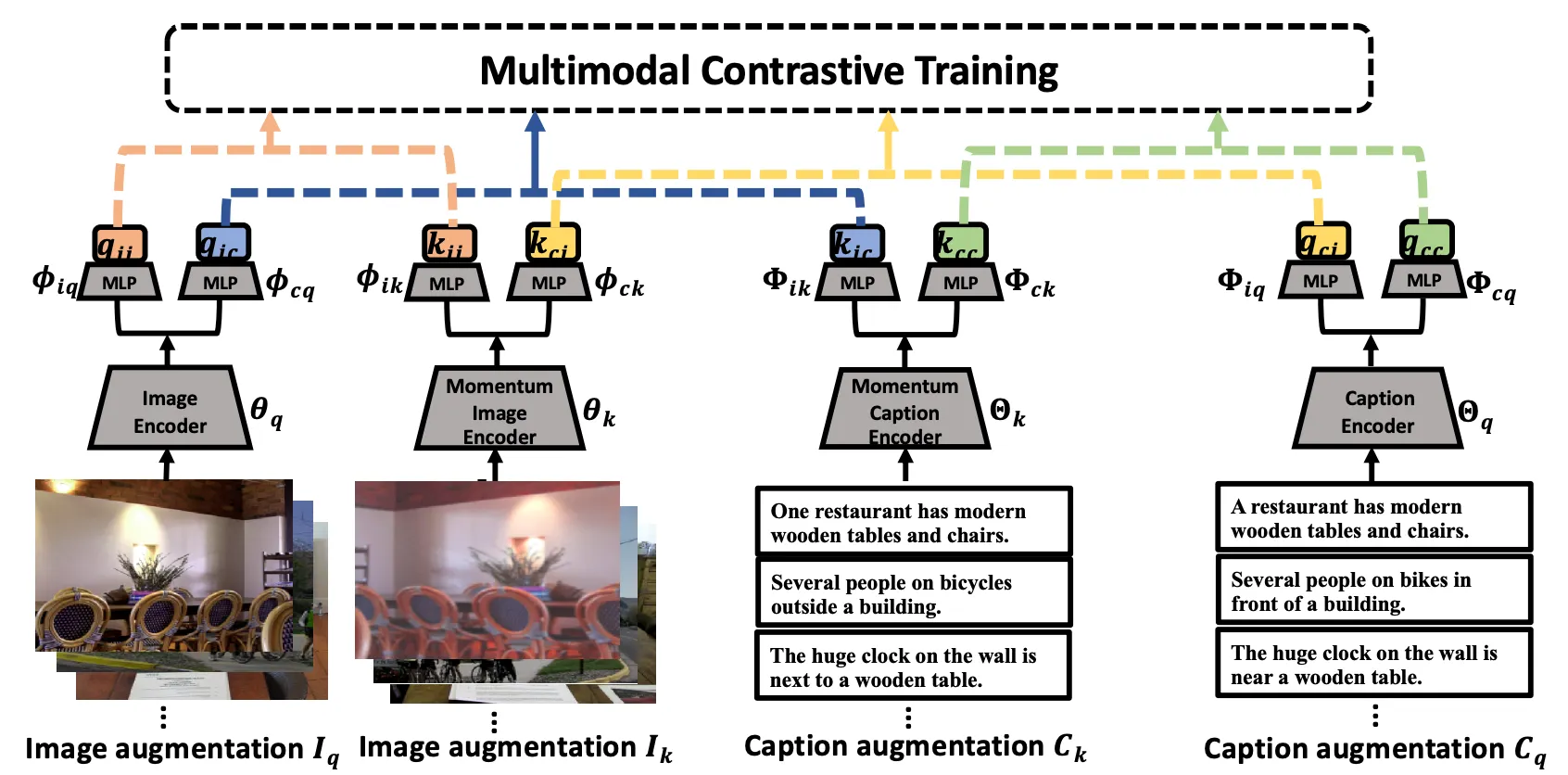
- 참고자료[6] Multimodal Contrastive Training for Visual Representation Learning 논문 그림
이 논문은 Multimodal Representation Learning에서 contrastvie learning은 다양한 모달리티의 데이터를 이용하여 시각적인 표현을 학습하는 접근법으로 intra-modal 및 inter-modal의 유사성 보존 목표의 조합에 의해 주도되고 다양한 contrastive loss 유형과 함께 multimodal 훈련을 통합 프레임워크에 포함했다는 특징을 보여준다[6].
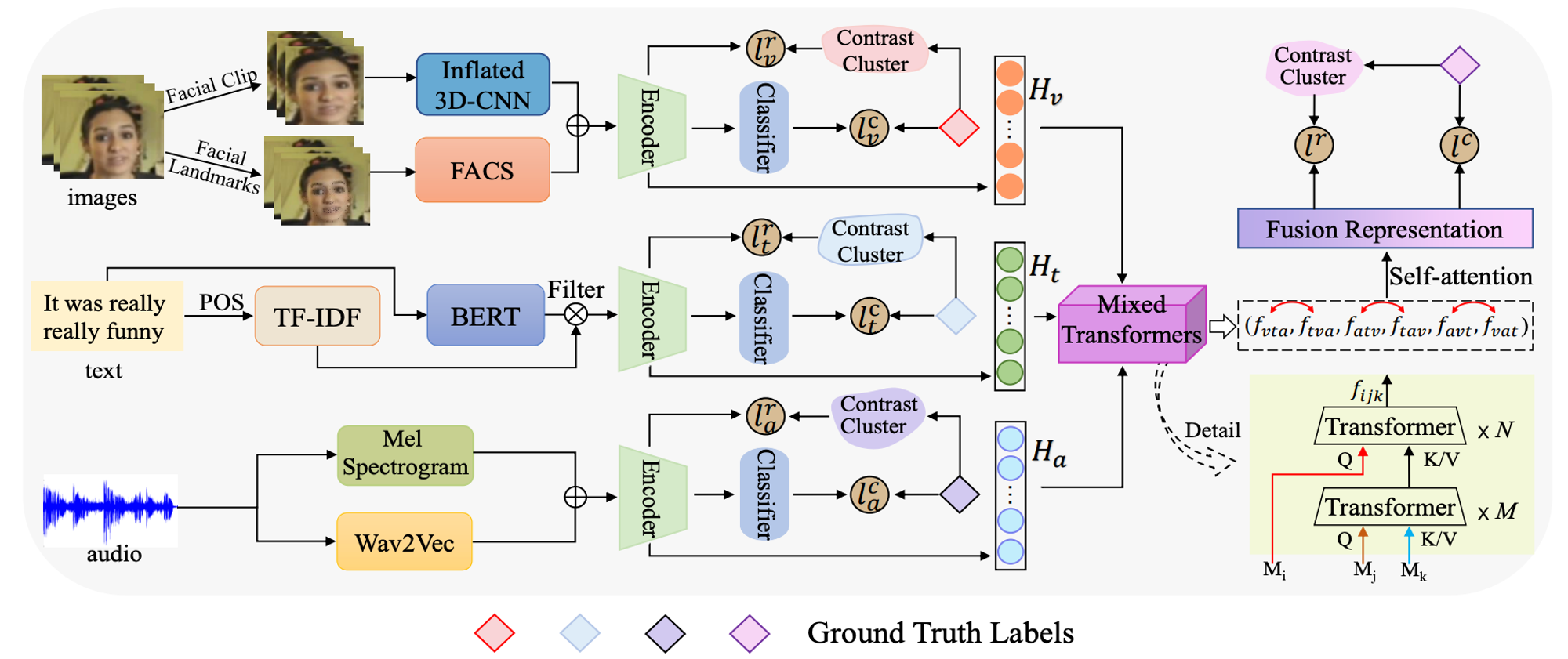
- 참고자료[20] Improving the Modality Representation with Multi-View Contrastive Learning for Multimodal Sentiment Analysis 논문 그림
Multimodal Representation Learning에서 contrastvie learning은 Multimodal Sentiment Analysis의 표현학습에 적용된다. 이 논문은 multi-view contrastive learning을 사용하여 강한 구별력을 가진 modal representation을 재구성하는 3단계 프레임워크를 제안한다[20].
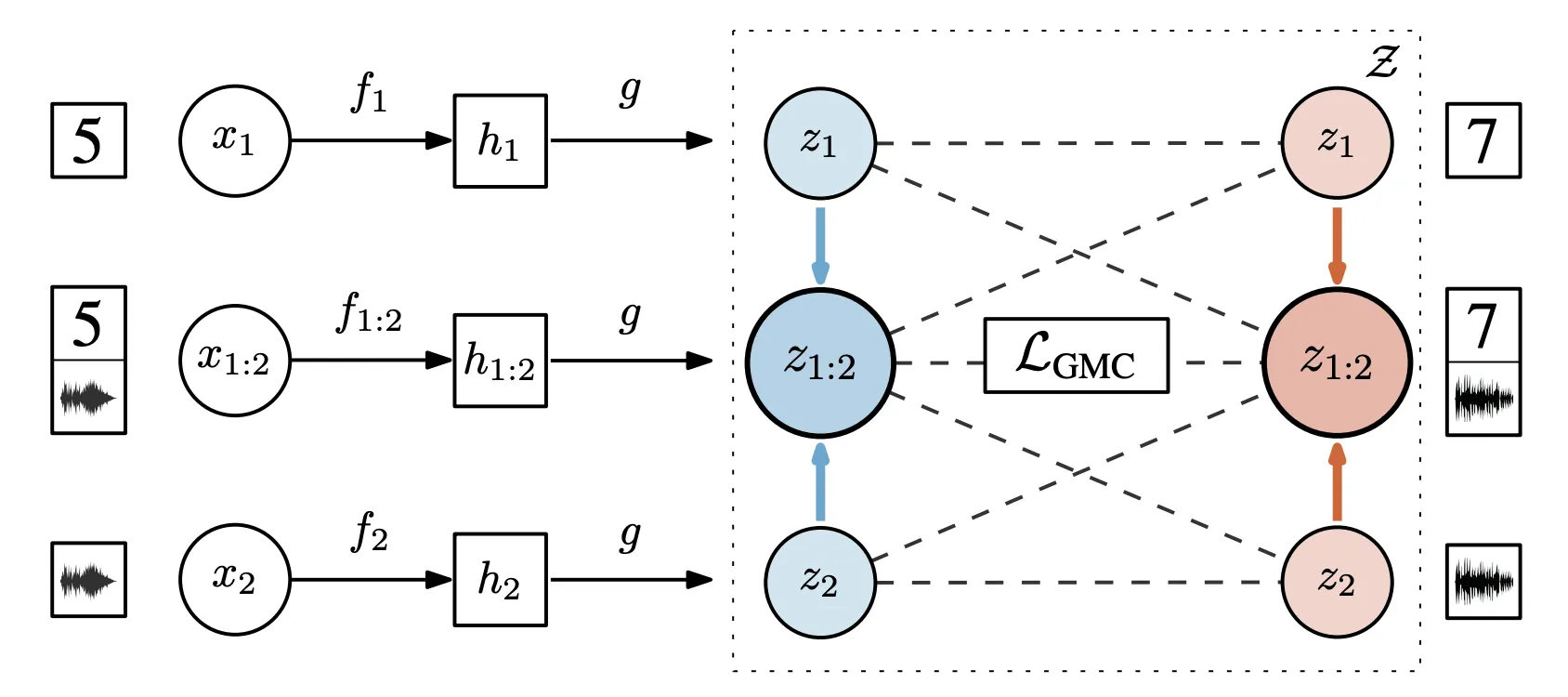
- 참고자료[21] Geometric Multimodal Contrastive Representation Learning 논문 그림
Geometric Multimodal Contrastive Representation Learning에서는 다양한 채널에서 얻은 데이터의 이질성으로 인해 테스트 시간에 누락된 modality에 대해 정보가 풍부한 multimodal 데이터의 표현을 학습할 수 있도록 Geometric Multimodal Contrastive를 제안한다[21].
5. Key works and Insights
정리하자면, Contrastive Learning은 self-supervised learning으로 유사한 이미지는 서로 가깝게, 동시에 다른 이미지는 서로 멀리 떨어지도록 이미지를 인코딩하는 방법이다. 즉 모델은 데이터셋의 일반적인 특징만 학습하며 어떤 이미지가 유사하고 다른지를 학습한다.
이와같은 Contrastive Learning의 장점은 레이블 없는 데이터를 사용하여 모델을 학습할 수 있다는 점으로 레이블링 비용이 많이 드는 경우 & 데이터셋 규모가 클 경우에 굉장히 유용하고 새로운 클래스가 들어와도 언제든 대응이 가능하고 일반적인 feature 표현이 가능하다는 점이다.
이에 반해 단점으로는 데이터 증강에 중점을 두고 있기 때문에 데이터 증강이 어려운 경우 성능저하가 발생할 수 있다는 문제가 있다.
이번 글을 통해 Contrastive Learning에 대해 정리해보았습니다.
생각보다 간단한 원리이지만 여전히 수많은 논문에서 사용/응용되고 있다는 것을 알 수 있었습니다. 특지 Self-supervised와 supervised learning 모두에서 적용될 수 있다는 점을 알 수 있었고, 하나의 모달리티를 학습하는 경우 외에 Multimodality를 학습할 때도 사용될 수 있다는 것을 알 수 있었습니다.
참고자료
1.
2.
3.
Jeff Z. HaoChen, Colin Wei and Tengyu Ma, “Understanding Deep Learning Algorithms that Leverage Unlabeled Data, Part 2: Contrastive Learning | SAIL Blog (stanford.edu)”
5.
Dan Fu, Mayee Chen, Megan Leszczynski and Chris Re, “Advances in Understanding, Improving, and Applying Contrastive Learning”
6.
Xin Yuan et al, “Multimodal Contrastive Training for Visual Representation Learning”, Adobe Research, 2022
7.
Razvan Brinzea et al, “Contrastive Learning with Cross-Modal Knowledge Mining for Human Activity Recognition”, Maastricht University
8.
9.
10.
11.
Michael U. Gutmann, Steven Kleinegesse, Benjamin Rhodes, “Statistical applciations of contrastive learning”, Behaviormetrika 49, 277-301(2022)
12.
Phuc H. Le-Khac, Graham Healy, Alan F. Smeaton, “Contrastice Representation Learning: A Framework and Review”, IEEE Access 2020
13.
AJ Maschinot, Jenny Huang, “Extending Contrastive Learning to the Supervised Setting”, Google Research
14.
Pranjal Kumar, Piyush Rawat, Siddhartha Chauhan, “Contrastive self-supervised learning: review, progress, challenges and future research directions”, International Journal of Multimedia Information Retrieval 2022
15.
16.
Ting Chen et al, “A Simple Framework for Contrastive Learning of Visual Representations”, PMLR 2020, by Google Research, Brain Team
17.
Ting Chen et al, “Big Self-Supervised Models are Strong Semi-Supervised Learners”, NeurIPS 2020, by Google Research, Brain Team
18.
Kaiming He et al, “Momentum Contrast for Unsupervised Visual Representation Learning”, CVPR 2020, by Facebook Research
19.
Shiyi Kong et al, “CL-MMAD: A Contrastive Learning Based Multimodal Software Runtime Anomaly Detection Method”, Applied Sciences 2023
20.
Peipei Liu et al, “Improving the Modality Representation with Multi-View Contrastive Learning for Multimodal Sentiment Analysis”, arXiv 2023
21.