
2022년 NeurIPS에서 Microsoft가 발표한 “FIBER:Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone” 논문에 대해 정리한 글입니다.
 Summary
SummaryFIBER는 Vision-Language 분야에서 Multimodal Fusion에 대한 연구로 coarse-to-fine pre-training 전략을 새롭게 제안했는데. 먼저 image-level의 objective를 학습한 후, image-text-box 데이터를 통해 더 세밀한 이해 능력을 얻기 위해 점진적으로 학습하는 end-to-end VLP 모델이다. FIBER는 기존 연구들보다 모든 측면에서의 성능이 뛰어났는데. 심지어 더 큰 규모로 사전 학습된 다른 모델들보다도 나은 성능을 보여준다. Ablation study를 통해 모델과 제안한 프레임워크의 구성이 최적임을 입증하였다.
Insights1.
VL task에 대해 다양한 수준의 이해를 제공하는 최초의 end-to-end VLP 모델 제안.
2.
Imaget-Text 기반의 Coarse-grained Pre-training과 Image-Text-Box 기반의 Fine-grained Pre-Training 두 단계로 나누어져 학습이 진행됨.
3.
Image와 Text backbone 사이에 Cross-attention을 넣은 multimodal fusion 모델.
4.
이때 Cross-attention을 switch-on/off 할 수 있어서 dual encoder와 fusion encoder 간의 빠른 전환 가능 및 grounding/object detection 등으로의 확장 용이해짐.
Future works1.
모델 자체 확장 및 프레임워크를 다른 modality로 확장할 계획.
2.
pre-training 데이터에 존재하는 바람직하지 않은 사회적 편견을 잠재적으로 물려받을 가능성 존재.
→ 리얼월드 테스크에 적용하려면 데이터에 대한 debiasing과 filtering 필요.
3.
pre-training하면서 발생하는 environmental cost를 줄여볼 계획.

시작하기에 앞서 Multimodal Fusion이란, 다른 종류의 데이터를 결합하여 더 이해하기 쉽거나 유용한 정보를 생성하는 과정으로, 이미지/오디오와 같은 여러 모달리티에서 고차원 입력을 동시에 처리하고 융합하는 것을 의미한다. 장점으로는 우선 각 모달리티가 가진 불완전하거나 신뢰할 수 없는 정보를 보완하고 통합하여 더 지능적으로 추론할 수 있게 해준다. 또한 여러 모달리티의 데이터를 결합함으로 각 모달리티의 독립적인 처리과정에서 발생할 수 있는 정보손실을 줄이고 풍부하고 다양한 특징을 추출할 수 있게 해준다.
그럼 본격적으로 FIBER 논문에 대해 소개한다.
기존 방식과의 차이점
기존 방식들은 이미지에 대한 높은 수준의 이해도를 테스트하는 테스크를 목표로 하거나 region-level에서의 이해도만을 목표로 한다. 이와 다르게 FIBER는 image와 text backbone 사이에 cross-attention을 추가해서 multimodal fusion을 추진하므로 메모리와 성능 측면에서 이점을 제공한다.
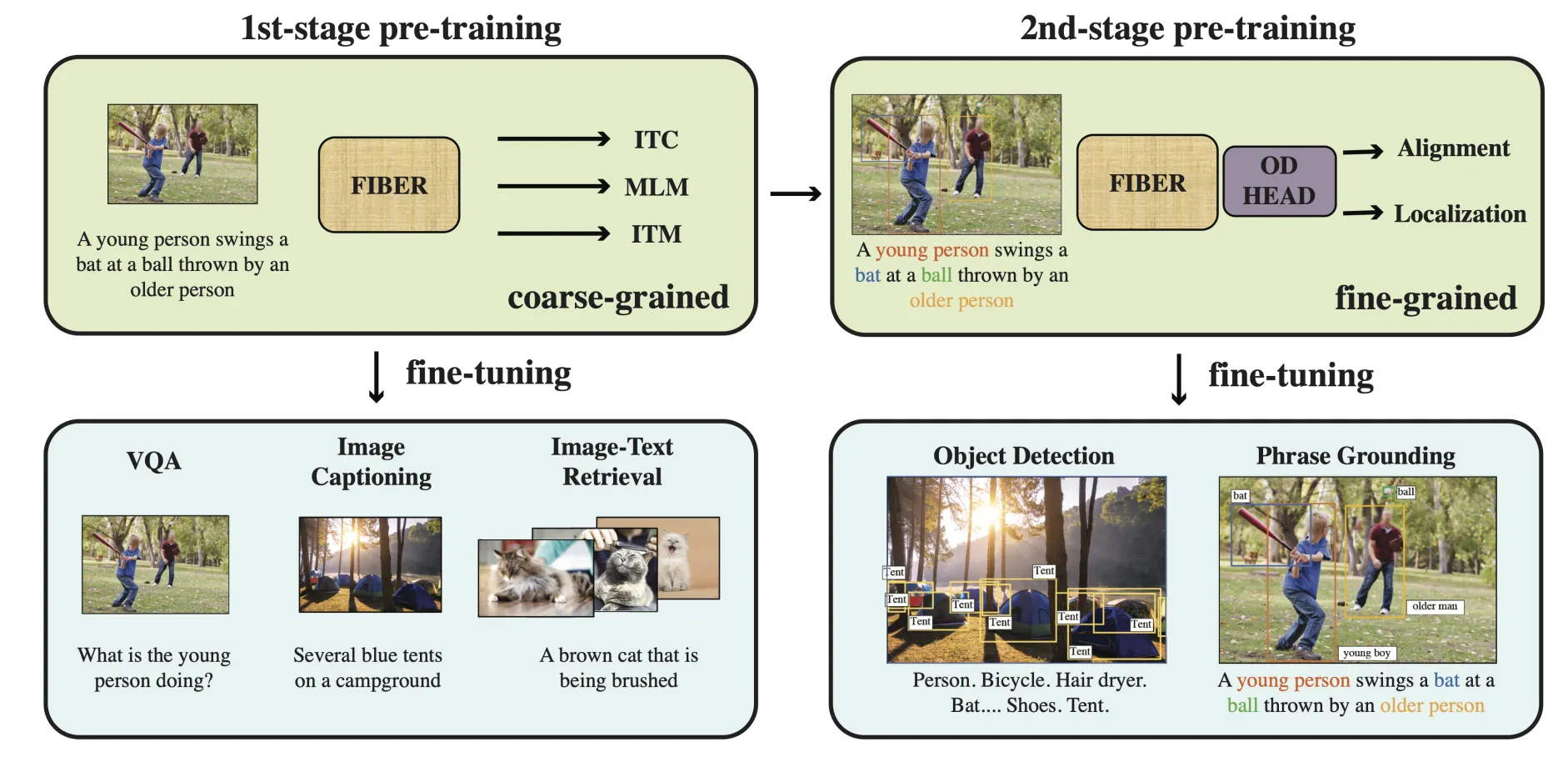
(그림1)논문에서 제안한 vision-language task를 위한 coarse-to-fine pre-training framework 그림.

(그림2)FIBER 모델 아키텍처 그림. image backbone으로 Swin Transformer가 사용됨.
또한 두 가지 단계로 나누어져서 학습이 진행되는데,
•
image-text 데이터를 기반으로 하는 coarse-grained pre-training
•
image-text-box 데이터를 기반으로 하는 fine-grained pre-training
이를 통해 FIBER는 image-level과 region-levle을 아우르는 Vision-Language(VL)을 할 수 있는 최초의 end-to-end VLP(VL Pre-training) 모델이라는 걸 알 수 있다.
위에서 언급한 내용들에 대해 아래에서 더 자세하게 살펴보도록 한다.
FIBER 아키텍처
간단하게 설명하자면, 그림2와 같이 FIBER는
•
cross-attention module을 image와 text backbone에 직접 삽입하는 것을 제안함
•
cross-attention module을 끄고 키는 방식으로 dual encoder(fast image retrieval)와 fusion encoder(VQA, Captioning) 간의 빠른 전환을 가능하게 함
•
visual grounding, referring expression comprehension, object detection 등으로 확장가능함
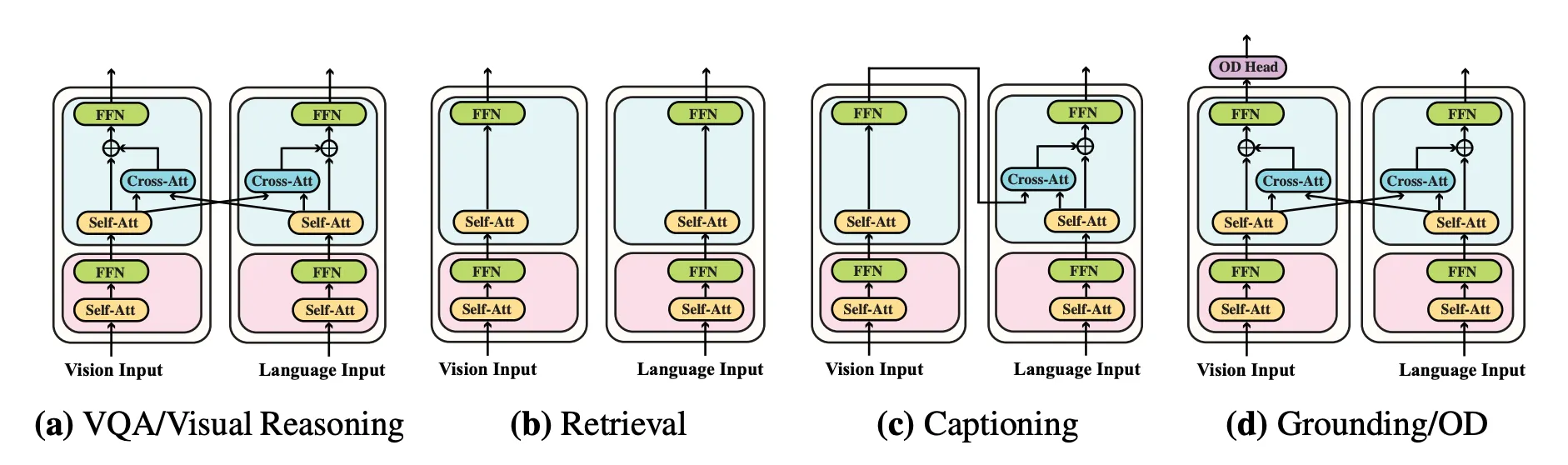
(그림3)다양한 downstream VL task에서 사용되는 FIBER 그림.
FIBER는 coarse-to-fine two-stage pipeline으로 구성됨
•
coarse-grained pre-training
◦
384x384 저해상도 이미지를 입력으로 받으며, image-text matching, masked language modeing, image-text contrastvie losses로 사전학습됨.
◦
pre-trained model은 VQA(그림3. a)와 Captioning(그림3. c) 테스크을 위해 fine-tuning될 수 있고, cross-attention module을 끔으로 빠른 image-text retrieval(그림3. b)를 위한 dual encoder로서 사용되기도 한다.
•
fine-grained pre-training
◦
object detection head에 랜덤하게 초기화된 파라미터 외에 coarse pre-trained 모델을 initialization으로 사용
◦
800x1,333 고해상도 이미지를 입력으로 받고, bounding box localization loss 및 word-region alignment loss로 사전훈련
◦
pre-training에는 ground-truth box annotation이 포함된 image-text-box 데이터를 사용하고, 모델은 grounding이나 object detection(그림3. d) 테스크를 위해 직접 fine-tuning할 수 있다.
•
fine-grained pre-training과 비교하자면, coarse-grained pre-training은 웹에서 쉽게 수집할 수 있는 paired image-text 데이터만 필요하기 때문에 확장이 용이하다는 장점 존재.
•
fine-grained pre-training에 coarse-grained pre-training 모델의 파라미터를 재사용하면, 대량의 box-level annotated data에 대한 요구사항을 완화할 수 있는 장점이 존재.
Method
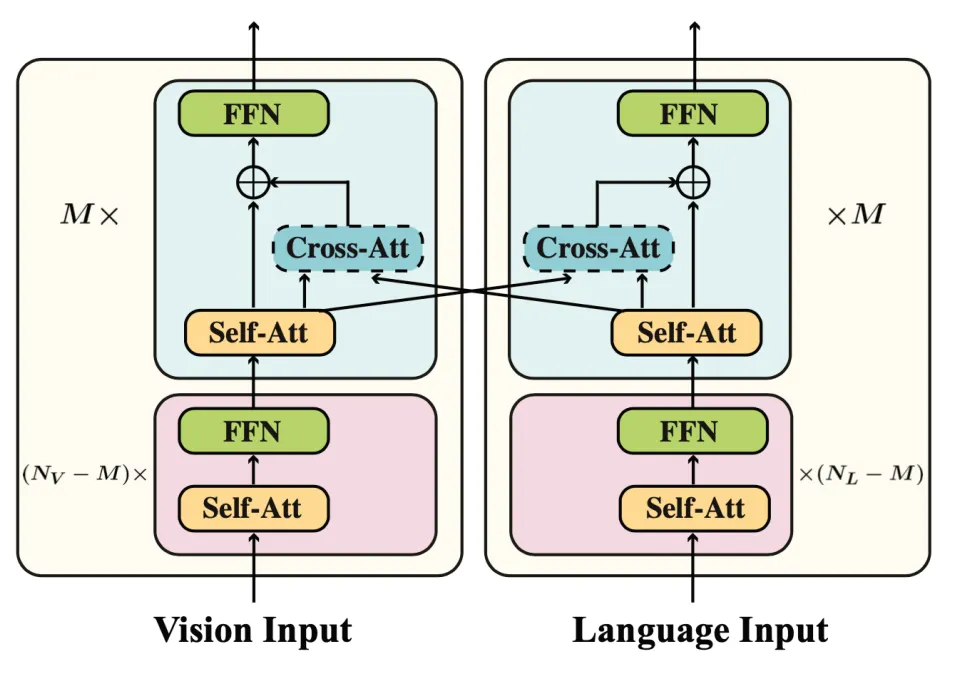
(그림2)FIBER 모델 아키텍처 그림. image backbone으로 Swin Transformer가 사용됨.

(그림4)backbone에서 fusion을 수행하는 과정을 나타낸 그림.
Fusion in the Backbone
그림2와 같이 FIBER 모델은 다른 modality fusion module을 위에 쌓는 모델들과 다르게 vision/language backbone의 상단에 modality fusion을 삽입하고, cross-modal layers에 대한 gating 메카니즘을 포함한다.

간단하게 말하자면, FIBER는 Vision-Language backbone에 동일한 수의 Cross-Attention layers를 추가한 구조이다. 다시말해, gating 메카니즘을 포함한 cross-attention layers를 추가하면 모델 학습을 시작할 때 backbone의 원래 computational 흐름에 영향을 주지 않으면서 동시에 cross-modal 간의 상호작용이 가능해진다. 또한 그림4에서와 같이 알파를 0으로 설정하여 인터렉션을 쉽게 껐다 켤 수도 있다(switch-on&off).
이처럼 backbone 위에 수많은 transformer layer를 쌓는 다른 모델들과 다르게, cross-attention layer를 추가하기 때문에 light-weight이고, memory-efficient가 좋다.
Coarse-to-Fine Pre-training
이미지 측면에서 region-level 출력을 생성해야 하는지 여부에 따라 VL 테스크를 두가지 카테고리로 나눈다. 이때 본 논문은 “두 테스크는 특징적으로 다르지만 VL fusion이 필요하고, 모델 간에 서로 가능한 많은 파라미터를 공유하는게 유용하지 않을까”라는 가설을 세우고 아래와 같은 two-stage pre-training을 진행한다.
1.
저해상도 이미지에 대해 image-level 목표를 가지고 모델을 사전 학습한 다음(coarse-grained)
2.
입력 image의 해상도가 더 높은 region-level 목표를 가지고 추가 사전 학습을 수행(fine-grained)
이와 같이 two-stage pre-training을 진행하는데, 첫번째 단계의 coarse-grained supervision 덕분에 두번째 단계에서 공유된 모든 파라미터에 대해 initialization을 제공할 수 있게 됐다는걸 알 수 있다. 이 두 단계의 사전 훈련을 FIBER에서 Backbone으로 사용한다.
•
coarse-grained pre-training
VQA 및 Captioning의 경우, Masked Language Modeling(MLM), Image-Text Matching(ITM), Image-Text Contrastive(ITC)가 ViT 기반 VLP 모델에 유용하다는 게 이전 연구들에 의해 이미 입증됨. 이 논문 역시 MLM, ITM, ITC를 모두 사용해서 사전학습을 진행한다.
◦
ITC (Image-Text Contrastive)
▪
추가된 cross- attention modules이 꺼져있으므로 (switch-off) 이때 FIBER는 dual encoder로 작동.
▪
image-caption pair 데이터셋이 주어지면, 먼저 modality fusion 없이, vision과 language 각각 representation을 계산한 다음, contrastive loss를 통해 positive image-text pair 사이의 유사성을 최대화하고, 나머지 negative image-text pair의 유사성을 최소화한다.
•
fine-grained pre-training
대부분의 VL 아키텍처들은 vision과 language input encoding에 우리가 흔히 아는 transformer을 사용하지만 text 토큰들과 달리 image entities는 동일한 스케일로 존재하지 않는다. 다양한 스케일에서 image를 정확하게 모델링할 수 있는 능력이 중요한 object detection에서는 높은 해상도 이미지를 사용하는데, 이는 입력 시퀀스 길이에 따라 4제곱으로 확장되는 transformer를 사용할 때 문제가 된다.
◦
따라서 FIBER에는 image encoder로 Swin Transformer를 사용하는데, 이는 이미지의 hierarchical representation을 제공하는 동시에 linear complexity도 제공
◦
이러한 multi-scale representation을 object detection 훈련을 위해 FPN을 사용하여 결합
◦
fine-grained pre-training을 위해 cross-attention module을 킴. 즉, FIBER를 fusion encoder로 사용(switch-on)
◦
이렇게 하면 FPN으로 전달되는 image representation은 이미 텍스트를 인식하고 있음. (이는 object detection head에서 이미지와 텍스트의 융합이 이루어지는 GLIP과 비교했을 때 중요한 차이점.)
다시 정리하자면,
◦
Swin backbone에서 text-aware image features를 추출하고
◦
◦

종합하면 FIBER는 image region과 text phrases 사이의 대응 관계를 학습하여, 동일한 프레임워크를 통해 phrase grounding과 object detection을 처리할 수 있다. (*이때 여기서는 ATSS framework를 사용했지만 FIBER는 Faster-RCNN이나 RetinaNet 같은 object detector과도 결합할 수 있다.)
Adaptation to Downstream Tasks

(그림3)다양한 downstream VL task에서 사용되는 FIBER 그림.
•
VQA/Visual Reasoning - VL classification(그림3. a)
◦
FIBER를 fusion encoder로 사용(switch-on)
◦
VL backbone의 최상위 m-layers가 서로 상호작용하여 multimodal representation을 생성
◦
두 modality의 최종 layer representation을 서로 concat하여 VQA/Visual Reasoning과 같은 테스크에 대한 최종 출력을 생성
•
Retrieval(그림3. b)
◦
빠른 image-text retrieval을 위해 dual encoder로 사용(switch-off)
•
Captioning(그림3. c)
◦
image-to-text cross-attention만 유지하고
◦
decoding 측면에서 causal masks를 사용하는 방식으로 FIBER를 적용
◦
최종 image encoding layer representation은 cross-attention module에 공급됨
•
Phrase Grounding, Object Detection, Referring Expression Comprehension(그림3. d)
◦
FIBER를 fusion encoder로 사용(switch-on)
◦
fine-grained pre-training 중에 도입된 OD-Head는 FIBER가 추출한 multimodal representation으로 이미 language-aware image feature를 수신
◦
pre-trained model은 이러한 작업에 별도의 수정없이 바로 사용됨
Experiments
Pre-training Datasets.
•
coarse-grained pre-training
•

•
Architecture
◦
Swin-Base and RoBERTa-Base for vision & text backbone
▪
이때 backbone은 uni-modal pre-training으로 weight가 초기화됨.
◦
Insert Cross-Attention blocks into the top 6-blocks of vision & text encoder
◦
input resolution
▪
coarse-grained pre-training: 384x384
▪
fine-grained pre-training: 800x1,333
◦
using hierarchical vision transformer + multimodal fusion being in the backbone
•
Implementation Details
◦
coarse-grained pre-training
▪
steps(100k). batch_size(4,096). GPU(64 A100)
▪
AdamW, peak_learning_rate: backbone (1e-4) & corss-modal parameter(5e-4)
▪
linear warmup over the first 1k steps and linear decay
◦
fine-grained pre-training
▪
steps(800k). batch_size(46). GPU(64 V100)
▪
learning_rate: language backbone(1e-5). rest (1e-4) & weight decay(0.01)
▪
linear warmup over the first 2k steps and constant learning rate
(* 더 자세한 사항은 논문 참고)
Results on Downstreams Tasks
•
Vision-Language Classification & Retrieval

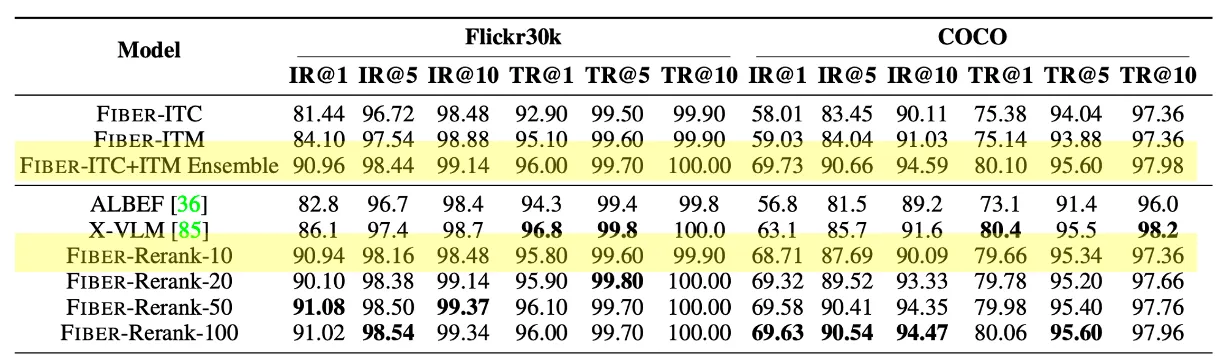
(표1)VL Classification과 Retrieval 실험 결과표.
•
Image-Text Retrieval
◦
Flickr30k, COCO 데이터셋으로 테스트.
◦
fusion encoder는 retrieval tasks에서 dual encoder를 큰 차이로 능가함.
◦
각 image-caption pair에 대해 유사도 점수를 합산하여 두 모델을 직접 조합하면 엄청난 개선 야기.
◦
Reranking을 수행하여 두 전략의 강점을 결합하는 방법을 수행하면, 효율성과 성능 간의 균형을 제공하고, 상위 10개의 인스턴스의 순위를 재조정하는 것만으로도 앙상블과 비슷한 성능 달성 가능(표2).
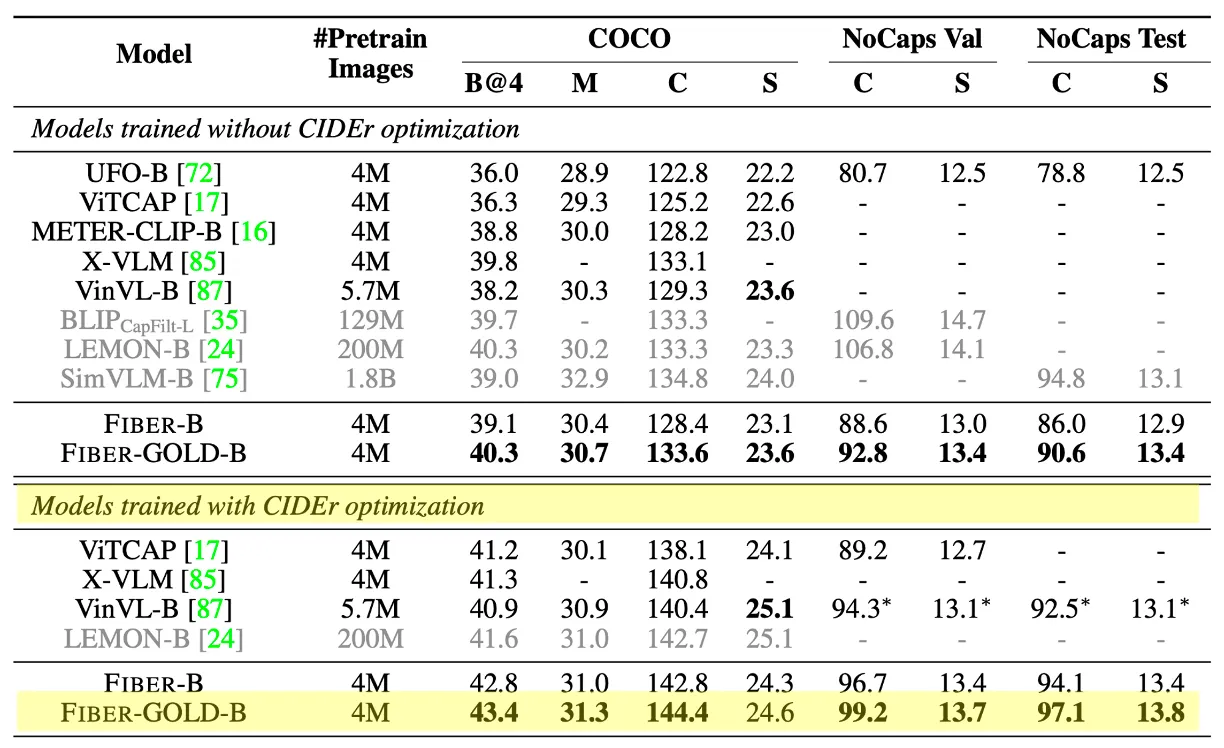
(표3)Image Captioning 상의 base-size model 실험 결과표.
•
Image Captioning
◦
◦
기본 크기 모델에 대해 COCO에서 CIDEr 점수를 설정. FIBER가 캡션을 수행하도록 사전 학습하지 않았다는 점을 고려했을 대, 엄청난 일반화 능력을 입증

(표4)Flickr30k entities 데이터셋으로 Phrase Grounding 실험한 결과표.
•
Phrase Grounding
◦
Flickr30k entities grounding 데이터셋으로 테스트
◦
Recall@1이 후속 fine-tuning 없이 87.4 달성: 25배나 적게 fine-grained 데이터를 사용하는데도 기존의 SOTA를 뛰어넘는 결과
▪
대규모 웹 말뭉치의 값비싼 pseudo-labelling과 이렇게 생성된 fine-grained 데이터에 대한 후속 고해상도 훈련에 의존하는 대신, image-text coarse-grained pre-training을 더 잘 활용 가능.

(표5)Referring Expression Comprehension 데이터셋으로 실험한 결과표.
•
Referring Expression Comprehension
◦
referring expression에 대한 bounding box를 직접 예측
◦
RefCOCO/RefCOCO+/RefCOCOg 데이터셋으로 테스트
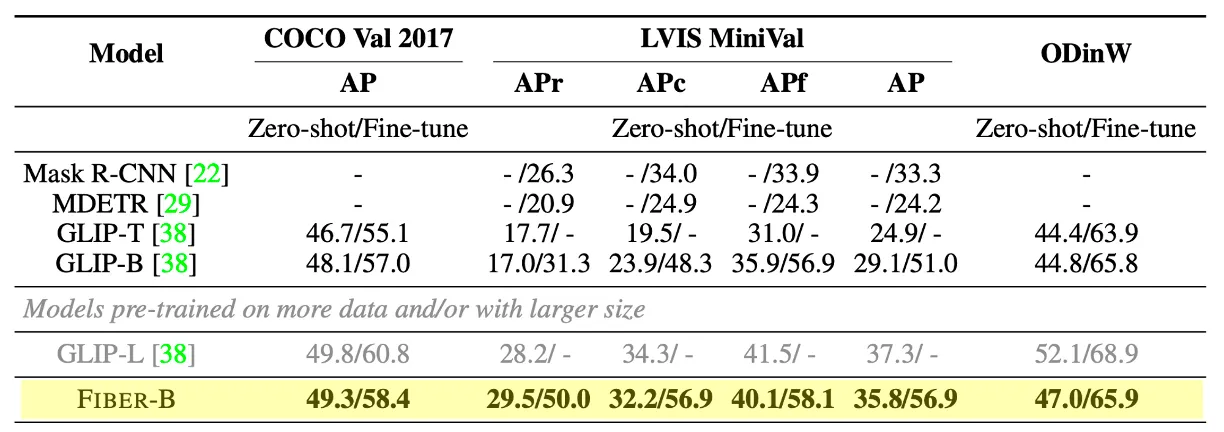
(표6)Object Detection을 위해 Zero-shot transfer/fine-tuning 실험 결과표
•
Object Detection
◦
COCO, LVIS 데이터셋으로 테스트 (* LVIS: obejct classes의 long-tail로 구성되어 있고, 모델의 일반화 기능과 class의 불균형에 대한 견고성을 평가하는데 널리 사용되는 test-bed.)
◦
APr(Average Precision on rare objects)지표에서 더 큰 모델이자 25배 더 fine-grained된 GLIP-L보다 우수한 성능 보임
◦
다양한 도메인에 걸친 13개의 ODinW 데이터셋에 대한 zero-shot 및 fine-tuning을 보면 이전 SOTA에 비해 우수한 성능향상을 보임
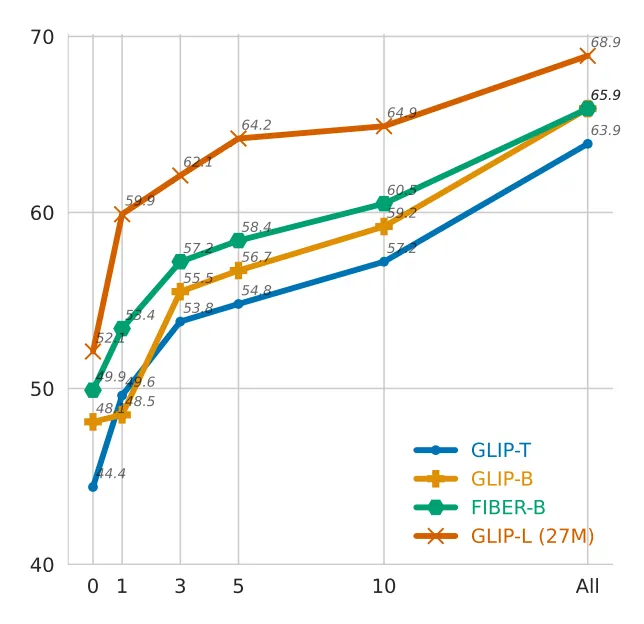
◦
위 그림, 이 13개 데이터셋에 대해 집계된 zero-shot 결과를 보면, 동일하게 fine-training된 데이터로 훈련된 GLIP-B에 비해 더 나은 데이터 효율성 보임
Ablation Study
•
Ablation Study on the Fusion Strategies.
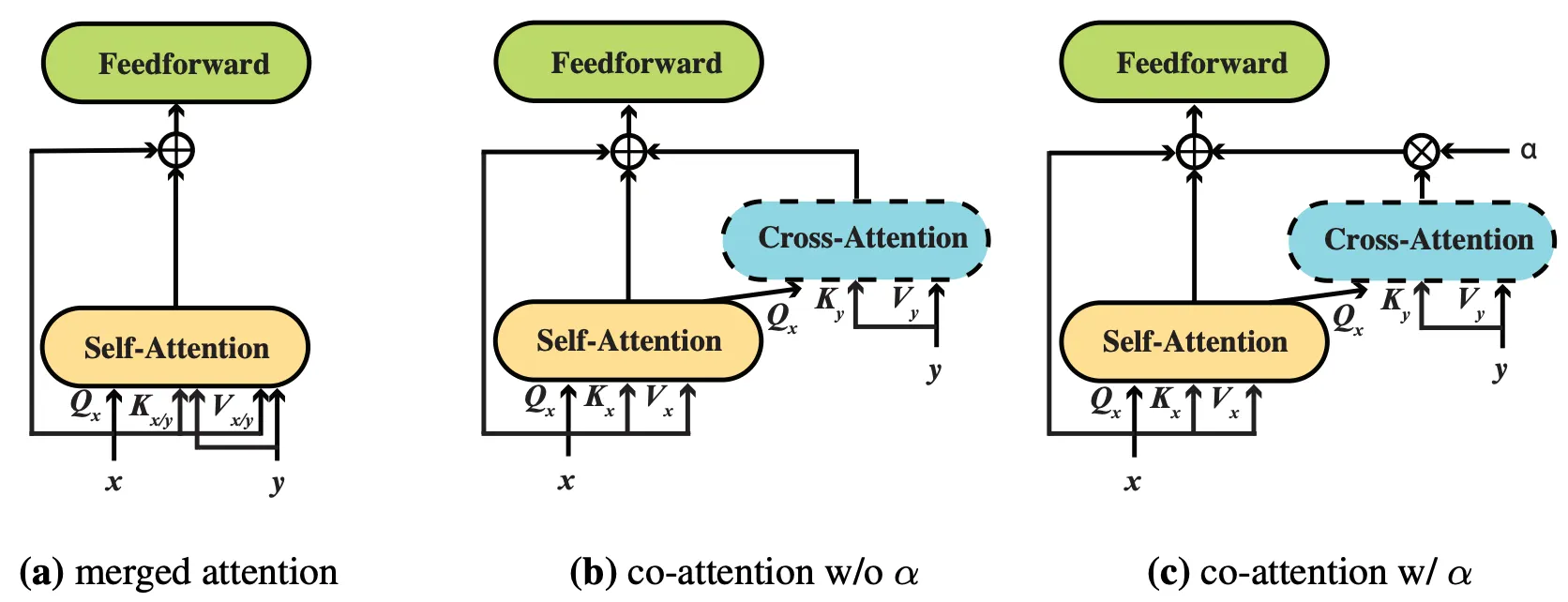
(그림5) Backbone에서의 fusion을 위한 다양한 전략들

(표7) Ablation study on the fusion strategies.
◦
표7을 보면, 효율성을 위해 VLP를 수행하지 않고, 모델을 직접 fine-tuning하여 세가지 fusion strategies를 비교.
◦
Swin Transformer와 RoBERTa를 vision-text backbone으로 사용. 초기화를 위해 사전에 학습된 파라미터를 로드. 이미지 해상도는 224x224로 설정.
◦
Merged Attention과 Co-attention이 없어도 비슷한 성능에 도달하는 것 알 수 있음.
◦
를 도입한 후, Co-attention의 성능이 크게 개선된 것 확인 가능.
▪
backbone에서 fusion을 위한 명시적인 controlling/gating 메카니즘을 갖는 것이 중요함을 의미.
▪
여기서 fusion layer 수를 늘릴 수록 성능이 더 개선되는 걸 확인 가능.
⇒ 결론적으로, Ablation 결과에 따라, backbone의 상위 6-layer를 fusion하는 방식을 선택하면 정확도와 효울성 간의 트레이드오프를 달성할 수 있음.
•
Ablation study on Pre-training Objectives.

(표8) Ablation study on the pre-training objectives.
◦
coare-grained pre-training 단계에서 image conditioned MLM, hard negative mining ITM, ITC loss로 모델 사전훈련
◦
각각의 Pre-training objective를 생략하고 VQAv2 & Flickr30k retrieval tasks 에서 모델을 평가
◦
표8에서 알수 있듯, pre-training objective를 제거하면 성능 저하될 수 있고, ITM-hard 사용하면 VQA와 Retrieval task 모두 성능 개선 효과
◦
MLM은 VQA에 가장 효과적, 제거해도 Retrieval 성능은 저하 안됨
⇒ 결론적으로 모델이 좋은 성능을 얻기 위해서는 모든 objectives가 필요하다는 걸 보여줌.
•
Ablation study on the Two-Stage Pre-training.
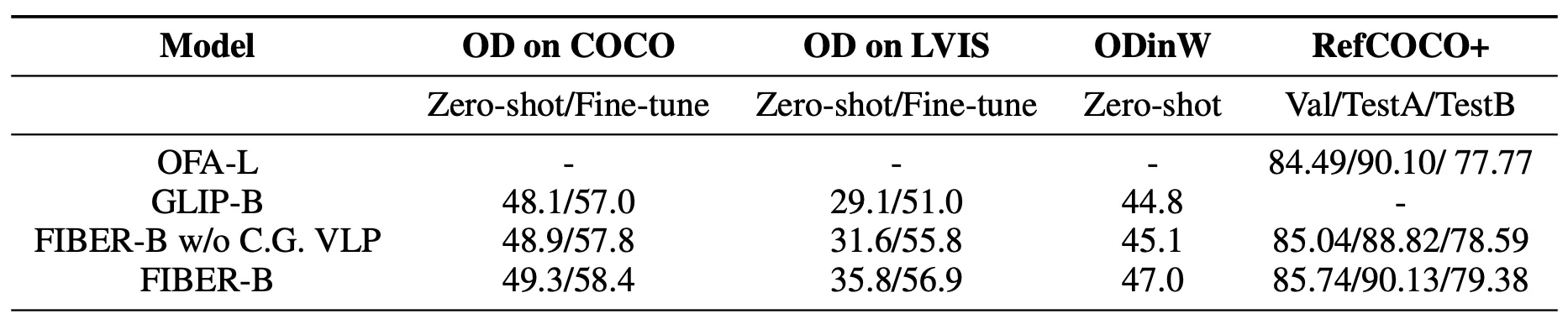
(표9) Ablation study on the Two-Stage Pre-training
◦
coarse-to-fine pre-training를 제거하고 image-text-box 데이터로만 모델을 사전 훈련한 결과
◦
표9를 보면 알 수 있듯, coarse-grained pre-training을 활용했을 때 두 task 모두 이득
◦
RefCOCO+에서도 coarse-grained pre-training은 더 많은 데이터로 훈련된 large-sized model 보다 더 나은 성능 얻을 수 있도록 FIBER에 도움 줌
⇒ coarse-grained pre-training이 없다면, FIBER와 GLIP 차이는 아키텍처 차이일 뿐인데. 결국 제안한 아키텍처의 효율성을 보여줌
•
Ablation study on Different Backbones.

(표10) Results of different vision and text backbones
◦
METER논문에서는 VLP 모델에 대해 서로 다른 vision-text backbone을 비교했고 본 논문 역시 그러한 설정을 실험함.
◦
Text encoder에는 BERT와 RoBERTa를 적용. Image encoder에는 CLIP-ViT와 Swin Transformer를 적용.
◦
표10을 보면 알 수 있듯 RoBERTa와 Swin Transformer가 VLP 전의 BERT와 CLIP-ViT 보다 약간 더 나은 성능 보임. (METER 결과와 유사)
▪
CLIP-ViT의 경우. 성능은 좀 더 나을지 몰라도 object detection과 같은 region-level tasks에 적용하기는 어렵다.
⇒ 본 논문에서 구상한 Swin Transformer와 RoBERTa가 최적의 구성임을 입증.
Uni-modal backbone 뒤에 fusion을 위한 트랜스포머 레이어가 있는 기존 모델들과는 다르게, FIBER는 이미지와 텍스트 backbone에 Cross-attention을 넣어 Multimodal-Fusion model을 제안했고, 저자는 coarse-grained image-level을 통해 학습한 다음, region-level을 통해 더 세분화된 region-level의 이해를 얻는 새로운 VLP 전략을 제안했습니다.
정리하자면 FIBER는 image-text retrieval, VQA, captioning과 같은 high-level과 region-level 이해 테스크를 모두 원활하게 처리할 수 있는 새로운 VL 모델 아키텍처라는데 큰 의의가 있다는 생각이 듭니다.